

W sumie to skąd wiemy, co program tak naprawdę robi? Czyli parę słów o ciężkim losie antywirusów (i naszym własnym)
Jak wielokrotnie wspominałem, jestem wdrożeniowcem. Miałem swego czasu pod opieką dość sporą, boleśnie homogeniczną sieć opartą o różne formy NT, która ze względu na miejsce zastosowania, była często raczona kodem dziwnego pochodzenia, o nieznanym i/lub niezrozumiałym działaniu. Użytkownicy potrafili na porządku dziennym przynosić szkodniki tak absurdalne i stworzone w tak pokręcony sposób, że miałem wrażenie, że pochodzą z innego wymiaru; nie tylko dlatego, że są napisane np. w Visual Basic 6.0 (a pochodzą z 2017 roku), ale również ze względu na to, że docelowo wykorzystują naiwność graniczącą z upośledzeniem. Do tego stopnia brakuje im subtelności i konsekwencji, że kojarzą mi się z oglądaniem międzywymiarowej kablówki z serialu Rick and Morty.

Wystarczy spojrzeć na ikonkę pliku „installl_flesh_player.HTA.exe” by wiedzieć, że nie jest do przyjazny przybysz. Nie potrzebujemy w tym celu narzędzi analitycznych, wystarczy intuicja i elementarny, zdrowy rozsądek. Ale jak ma to wiedzieć komputer? Skąd w ogóle wiadomo, co robi program, który chcemy uruchomić?

Zamiast przejść od razu do odpowiedzi (a brzmi ona „nie da się tego wiedzieć”), spróbujmy podzielić ten problem na mniejsze. Postawmy następujący problem do rozwiązania: skąd komputer ma wiedzieć, że uruchomi szkodliwy kod i jak go przed tym powstrzymać? Spróbujmy teraz odnaleźć satysfakcjonującą odpowiedź. Będzie to wymagało pewnej urokliwej przejażdżki po zawiłościach informatyki teoretycznej i psychologii. Po stokroć wolę psychologię od informatyki teoretycznej, zresztą w ogóle wolę ją od jakiejkolwiek informatyki, komputery są dla mnie strasznie męczące i w dodatku przeszkadzają mi w pracy.
Zacznijmy zatem od psychologii, a ściślej – od mechanizmu wyparcia. Zabrzmi on naturalnie jakoś na kształt „A po co badać, czy kod jest szkodliwy!? Wystarczy nie uruchamiać żadnego, poza pochodzącym z zaufanego źródła!”. Mowa tu rzecz jasna o takim prawdziwym, a nie udawanym zaufanym źródle. Czyli o takim, które podpisuje swój kod cyfrowo. Jest to przykład mechanizmu wyparcia, bo nie dość, że istnieje ryzyko skompromitowania zaufanego źródła, to jeszcze źródło może pozostać zaufanym – ale o niskiej renomie. Doskonałym przykładem będzie tu Sklep Google Play. Wszak sklep z aplikacjami jest centralnym źródłem zaufanym, tylko że niekoniecznie oznacza to wolność od szkodliwego oprogramowania. Oznacza to, że musimy się jednak zmierzyć z problemem inaczej. Alternatywą jest iść w zaparte - nie dać użytkownikowi uruchamiać żadnego kodu, zatrudnić administratora-oprawcę, a sklep z aplikacjami odgrodzić drutem kolczastym (jak Apple App Store). Prędzej czy później ktoś jednak popełni jakiś błąd. Rozwiązaniem nie będzie wtedy wymachiwanie rękami, pretensje i przykładne ukaranie winnych. Zamiast siać terror, należy próbować zaradzić problemom u źródła (niezaufanego).
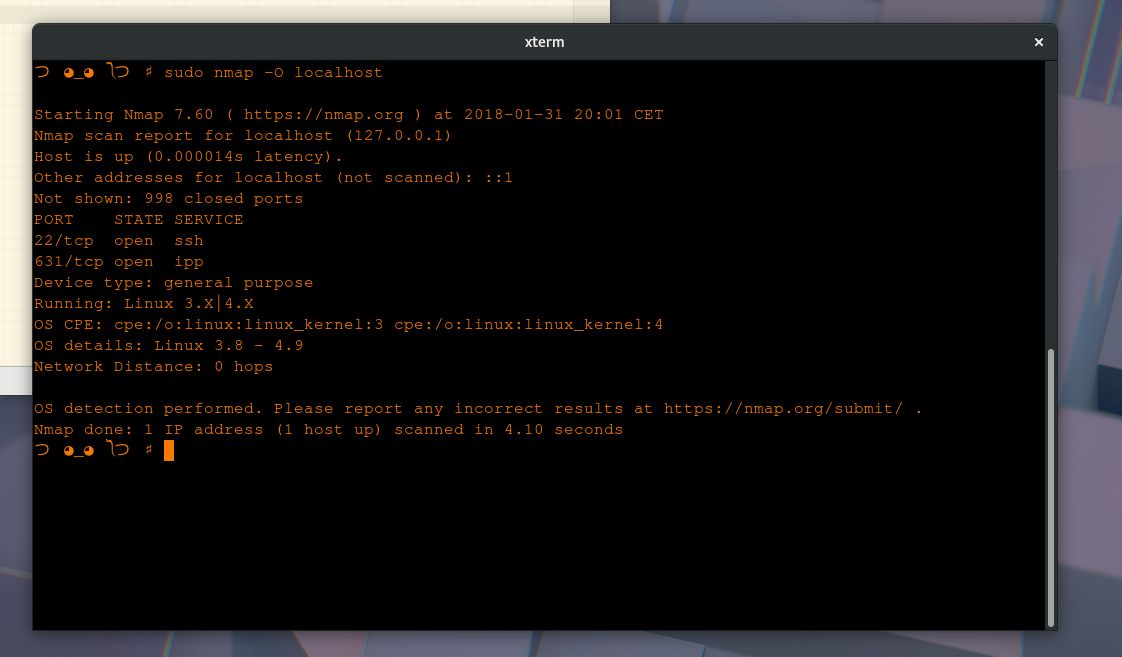
Wiedząc, że ludziom nie można ufać, a cały świat jest w zasadzie okropnym miejscem, wylęgarnią oszustów i prawdopodobnie regularnym piekłem, czego zwyczajnie nie zauważyliśmy – sięgamy po antywirusa. Oprogramowanie antywirusowe jest ustępstwem, przyznaniem się, że nie potrafimy tworzyć bezpiecznych systemów. Bezpieczne systemy są jednak bezużyteczne. Nie ma przecież mowy, żeby system – jak to mawia nmap – „ogólnego przeznaczenia” był bezpieczny. Takie systemy są z definicji niebezpieczne i jest to niemal powód do dumy, z powodów dość turingowskich i elementarnych. Skoro życie jest pełne niebezpieczeństw, niech komputery też będą! Najwyżej zatrudnimy wartownika. Będzie cyfrowy, więc będzie popełniał mniej błędów, niż człowiek, a przy okazji zdąży na jednej dniówce zbadać więcej podejrzanych programów.
Jednak klasyczne antywirusy tak naprawdę nie miały pojęcia, czy kod wykrywany przez nie jako szkodliwy jest taki w istocie. Antywirus rozwiązywał w praktyce łamigłówkę-sorter z klocków: jeżeli plik pasuje do wzorca, zostanie „wykryty”, zablokowany i przeniesiony do kwarantanny. Na jakiej podstawie? Sygnatur! Tworzonych i dzielnie aktualizowanych przez inżynierów-dostawców antywirusa. Innymi słowy, z definicji pozwalamy na wszystko, nie trudzimy się z wykrywaniem podejrzeń, a zagrożenia identyfikujemy na podstawie nędznie przygotowanych rysopisów. Takie antywirusy tym bardziej więc nie wiedziały, jak działają programy, które przyszło im pilnować.

Dzisiejsze antywirusy działają, naturalnie, zupełnie inaczej. Mają one rzecz jasna ochronę opartą o sygnatury, ale oferują też całkiem sporo nowości. Są też podatne na modę. Dlatego najnowsze produkty są smart i oferują „ochronę opartą o chmurę”, która w jakiś sposób jest „wspomagana przez głębokie uczenie”. Jest to nic ponad odrobinę mądrzejsze algorytmy behawioralne. I ponownie nie jest to rewolucja. Wprowadzenie do domowych antywirusów mechanizmów behawioralnych jest wszelako godne pochwały, przybliża bowiem zwykłych użytkowników do osiągnięć techniki oferowanych dotychczas głównie w kosztownych zestawach IDS/IPS (Intrusion Detection System). Moduł behawioralny przeszukuje stan i zachowanie systemu pod kątem groźnych symptomów, a nie groźnego kodu. Jednak z tego samego powodu, dla którego antywirusy nie wiedziały, jaki kod jest groźny, tak samo nie potrafią tego powiedzieć o zachowaniach. Może my tak naprawdę chcemy, żeby wrzucony do harmonogramu zadań program bez okna wysyłał napisany łamaną angielszczyzną spam z naszego komputera? Albo kopał bitcoiny po każdych dwóch sekundach nieaktywności? Who am I to judge? Dlatego moduł behawioralny też ma swoje definicje. Wspomaganie chmurowe polega tu jedynie na masowym zbieraniu telemetrii od nieświadomych klientów; jeśli 80% z nich będzie miało ciągle obciążony procesor przy takiej samej liście procesów (z czego połowę generują niepodpisane binaria), to producentowi łatwiej będzie wymyślić definicję zagrożenia i nie będzie nawet musiał zastawiać wabików (honeypotów). Nie wspominając już w ogóle o tym, że takie postawienie sprawy zakłada, że szkodliwy kod zdążył się już wykonać! Szkodliwy kod nie wiadomo skąd, wykonujący nie wiadomo co, ale wykazujący pewne wspólne zachowania. Fantastycznie. To ma być takie mądre?
Przed modą na moduły behawioralne, społecznościowe i chmurowe, krzykiem mody przez długie lata był mechanizm heurystyczny. Przedstawia się go w skrócie jako metodę wykrywania dotychczas nieznanych zagrożeń, na podstawie potencjalnych działań, które program miałby wykonywać. Takie wykrywanie w domyśle nie potrzebowałoby definicji, ale to nadużycie. Silnik heurystyczny również musi posiadać zbiór informacji na temat szkodliwych działań. Po prostu w przeciwieństwie do mechanizmu behawioralnego, heurystyka usiłuje „zgadywać”, co się dzieje na podstawie zawartości programu – bez jego uruchamiania.
W jaki sposób jest to możliwe? Skompilowany program można odpytać narzędziami programistycznymi o wiele interesujących detali, jak to, do jakich bibliotek się linkuje i co usiłuje z nich wyciągnąć, do jakich plików ma potencjał się odwoływać i czy uruchamia jakiekolwiek mechanizmy sieciowe. Wydawałoby się zatem, że uzbrojeni w taką wiedzę dysponujemy całkowicie kompletnym zbiorem informacji, by stworzyć stuprocentowo skuteczny, bezbłędny antywirus heurystyczny. Tak jednak nie jest. Dlatego, że bez uruchomienia programu możemy tylko zgadywać, co zrobi.
Może się to wydawać nieintuicyjne. Również dla programistów, wszak widząc kod programu, bez jego uruchamiania, potrafimy mniej więcej dość do tego, o co w nim chodzi i ustrzec się przed szkodliwym kodem jeszcze przed jego wykonaniem. Ale komputer nie może tak zrobić. Brak mu wyobraźni. Niezależnie od zastosowanych mechanizmów odpytywania podejrzanego programu nie da się wiedzieć, co program robi bez uruchomienia go. Można jedynie zgadywać. A to dopiero początek problemu.
Ponieważ problem nierozstrzygalności przepływu algorytmów jest znany o wiele bardziej, niż byśmy chcieli, podjęto próby oszukiwania rzeczywistości. Skoro musimy uruchomić kod, by poznać jego szkodliwość, uruchommy go. W symulowanym środowisku. Podejrzany, nierozstrzygnięty kod jest „detonowany” w specjalnie przygotowanej piaskownicy, a następnie badane są efekty. Aby taka metoda działania antywirusa była akceptowalnie wydajna, piaskownice szyje się na miarę: sztuczne środowiska uruchomieniowe są dostarczane w oddzielnych obszarach pamięci i pracują na zwirtualizowanych uprawnieniach. „Runtime” jest maksymalnie okrojony, a sam badany program – jeżeli to możliwe – uruchamiany segmentami. Pełniejsze piaskownice są wykorzystywane przez twórców antywirusów, bo przeniesienie pełnego mechanizmu badawczego na komputery osobiste byłoby zbyt ciężkim przedsięwzięciem. Prowadzi to do słusznego wniosku, że tak prowadzona walka jest nierówna, mniejsza piaskownica wykryje mniej szkodliwych zachowań. Z kolei większa – upośledzi wydajność na tyle, że samowolne uruchomienie wirusów byłoby dla niej mniej obciążające. Nawet pomijając kwestie wydajnościowe napotykamy problemy, dokładniejsze piaskownice to większa złożoność. Większa złożoność to szansa na dziury w bezpieczeństwie w samych piaskownicach, eksponujące zagrożenie z powrotem do klienta. Takie ataki istotnie miały miejsce i od lat już nie są dywagacją wyłącznie teoretyczną.
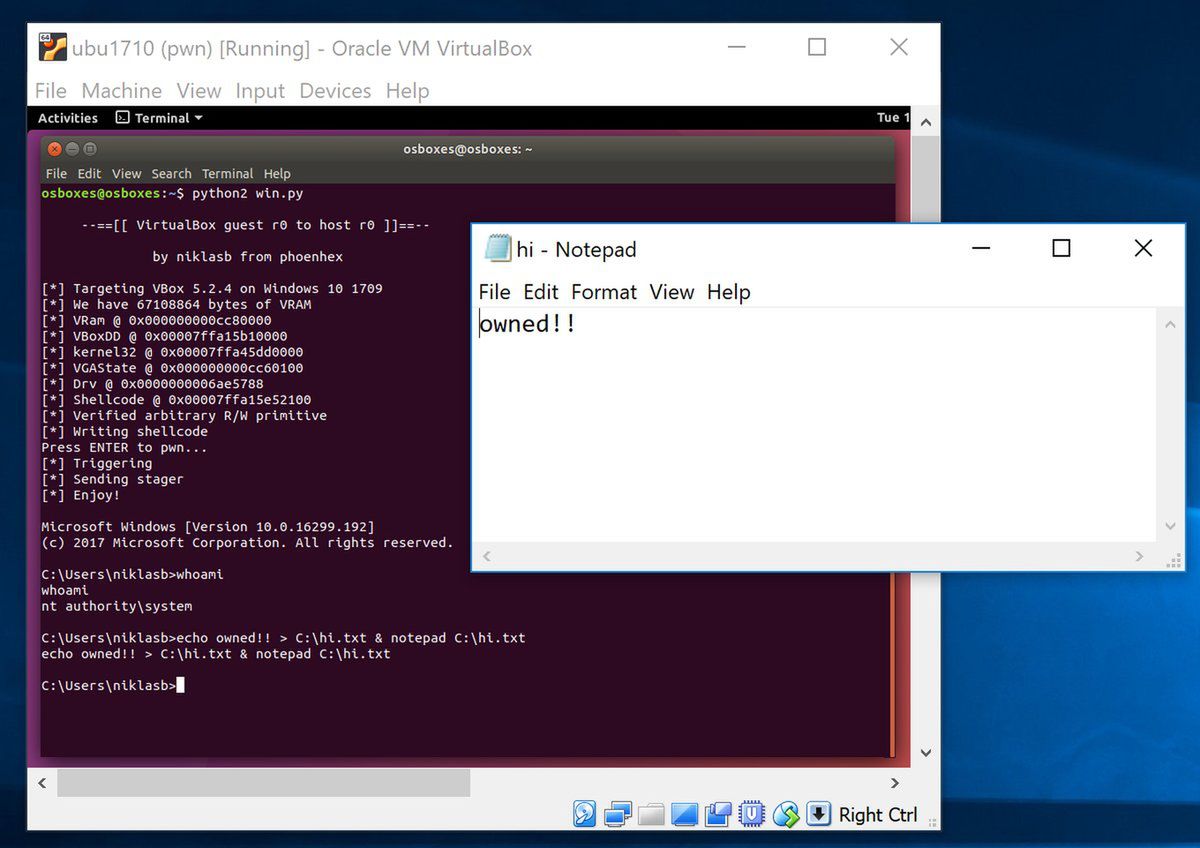
Ostateczną formą piaskownicy jest maszyna wirtualna - kompletny system operacyjny o stanie eksperymentalnie zgodnym z maszyną-hostem. Ta nieskończenie wyizolowana i bezpieczna metoda dorobiła się arsenału podatności, pozwalających na skakanie między maszynami albo wręcz do samego hipernadzorcy, poprzez takie cuda jak manipulowanie pamięcią, wykorzystywanie błędów projektowych, jak Meltdown, albo przepełnienie bufora w programowej implementacji kontrolera dyskietek. Zmierzamy tym samym do definicji fundamentalnych, niemal filozoficznych: z tego samego powodu, dla którego nie możemy stworzyć symulatora wszechświata (maszyna musiałaby wykazywać złożoność co najmniej mu równą, a jednocześnie zawierać sam wszechświat), nie możemy stworzyć narzędzia do zbadania kodu w bezpieczny sposób. Odpowiednio dokładne narzędzie samo w sobie będzie wymagało ochrony. Z tego nieintuicyjnego, a tak naprawdę boleśnie prostego powodu nie jesteśmy zdolni do napisania stuprocentowo skutecznego antywirusa.
Implikacje tego wniosku są w praktyce całkiem doniosłe dla każdego, kto używa elektroniki do czegoś więcej, niż pornografia i Facebook. Przede wszystkim dowodzą, jakimi geniuszami byli założyciele nieprzeciętnie nudnej dziedziny, jaką była informatyka teoretyczna. Turing i von Neumann opracowali założenia teoretyczne, które z naszej dzisiejszej perspektywy są tak naturalne i oczywiste, że aż trudno uwierzyć, że przywiązuje się do nich wagę. Turing opracował bowiem model teoretyczny, w którym liczby były wykorzystane do przechowywania dowolnych danych, a nie tylko stosownych dla specyficznego algorytmu danych ilościowych. Było to wprowadzenie do cyfrowego przetwarzania danych. Z kolei von Neumann opracował model systemu komputerowego z centralnym procesorem i adresowaną przestrzenią pamięci operacyjnej. Tak ujęte fundamenty rozpoczęły, jakże patetycznie dziś nazywaną, „erę cyfrową” – w praktyce oznacza to stworzenie narzędzi pozwalających na opisywanie dowolnej rzeczywistości i dokonywania na niej przekształceń. Przełamanie obliczeniowych ograniczeń wyobraźni i zdefiniowanie komputera ogólnego przeznaczenia (uniwersalnej maszyny cyfrowej) jest wydarzeniem o wadze historycznej i należy je rozpatrywać z perspektywy psychologii społecznej, a nie informatyki, nawet teoretycznej. Bowiem możliwość definiowania światów cyfrowych została ustanowiona wraz z całym bagażem życiowych niedoskonałości: systemy komputerowe, zupełnie jak życie, nie są idealne i zawsze kompletne. Są inherentnie niedoskonałe, a także nieprzewidywalne i niebezpieczne. Niniejsze wady najdonioślej potwierdzają potęgę osiągnięć Turinga i von Neumanna. Systemy idealne są bowiem nieludzkie.

Być może powyższy paragraf jest nieco zbyt metafizyczny, ale o to właśnie mi chodziło, gdy na początku wywodu o antywirusach powoływałem się na psychologię. Pozostaje mi zatem skonkludować temat, odwołując się tym razem do informatyki teoretycznej. Przytoczony już problem nierozstrzygalności jest jedną z postaci elementarnego problemu informatyki, jakim jest problem stopu. Stanowi on, że nie jest możliwe stworzenie uniwersalnego algorytmu, który niezawodnie rozstrzygałby dla każdego programu, czy ów program zakończy swoją pracę w skończonym czasie na idealnej maszynie (bez sprzętowych ograniczeń odpowiedzi i nieskończonym obszarem pamięci). Nierówna walka antywirusów ze szkodliwym oprogramowaniem i wiecznie wybrakowane modele bezpieczeństwa kolejnych wersji systemów operacyjnych wynikają pośrednio, acz niewątpliwie, właśnie z problemu stopu. Więc choćby przyszło tysiąc atletów i każdy zjadłby tysiąc kotletów, a maszyny wirtualne były niepenetrowalne i nieskończenie wydajne, to nawet wtedy odpowiedź na pytanie „co robi ten program” będzie niemożliwa, bo możliwych przebiegów będzie więcej, niż możliwych efektów.
Bardzo podoba mi się, że specyfika działania antywirusów dotyka swą naturą zagadnień tak fundamentalnych. Wszak problem stopu jest niczym innym, jak tylko dziedzinową postacią emanacji wielkiego twierdzenia Goedla o niezupełności i ograniczeniach systemów formalnych. „Żaden niesprzeczny system formalny, w którym da się wykonywać rozstrzygalne operacje efektywne nie jest wystarczający do tego, by udowodnić na sobie twierdzenia arytmetyki”. Innymi słowy, z natury rzeczy wynika, że zdań prawdziwych zawsze będzie więcej, niż zdań możliwych do udowodnienia.
Czyż to nie piękne?
:)






![Wysoka precyzja i wydajność w II gen. Logitech Pro X Superlight 2 DEX [Recenzja]](https://v.wpimg.pl/ODUwLmpwYCU0FTpeXwxtMHdNbgQZVWNmIFV2T19CdnMtRH1bXwMqJz1ZOx0TEyFqJRtjBB0QYCJsQXRVQBR-aWVDel9dQy4gMVp1XBEVYnY3RHsLREUucW1CfEMaByhmKA)
