

Naprawiamy dobreprogramy: automatyczne zajawki artykułów na stronie głównej i w listach publikacji
07.07.2018 | aktual.: 11.07.2018 13:01
W ostatnim czasie redakcja dobrychprogramów wprowadziła kilka istotnych zmian w funkcjonowaniu portalu. Jedną z nich było wprowadzenie zupełnie nowego wyglądu strony głównej, co wzbudziło wiele kontrowersji. Niektóre krytyczne komentarze zwracały uwagę na to, że nie są już pokazywane zajawki opublikowanych artykułów, przez co można się domyślać ich treści wyłącznie po tytule. W dobie clickbaitów uznałem, że nie jest to pozytywna zmiana. Wykorzystując świeżo zdobyte umiejętności pisania w JavaScripcie, zdecydowałem się napisać skrypt do Greasemonkey/Tampermonkey, który automatycznie będzie ściągał i pokazywał początkowe fragmenty publikacji, tak jak było w poprzedniej wersji DP.
Do zrozumienia całości wpisu przyda się podstawowa znajomość języków HTML i JavaScript, aczkolwiek efekty mojej pracy może na własnym sprzęcie zobaczyć każdy, kto korzysta z wtyczki Greasemonkey lub Tampermonkey: link do skryptu znajduje się pod koniec wpisu.
Zasada działania
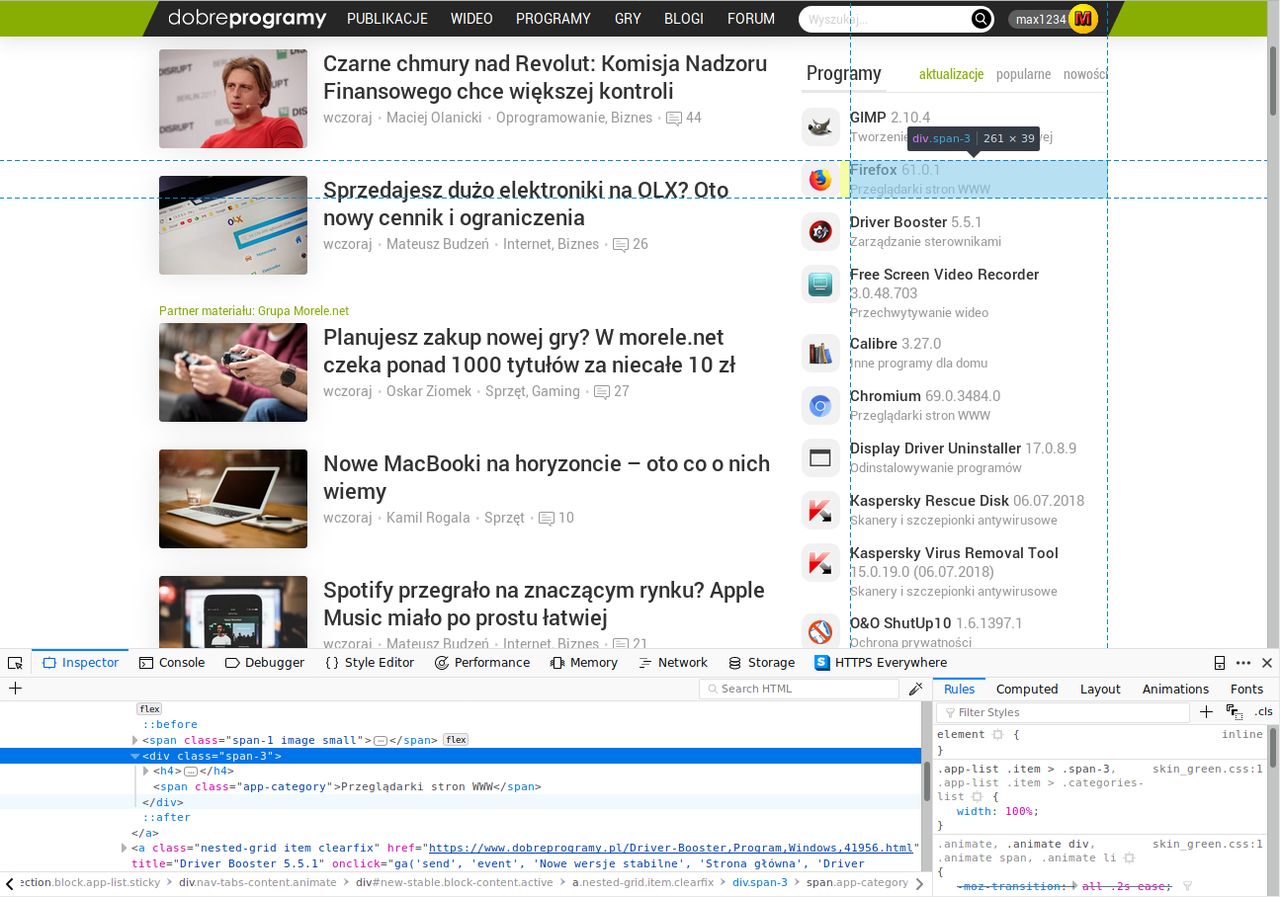
Na początek szybko przeanalizowałem strukturę strony głównej portalu. Niezwykle pomocny okazał się tutaj inspektor DOM w Firefoksie. Rzut oka na blok artykułowy zaznaczony na obrazku pozwolił mi ustalić, że tytuł publikacji wraz z innymi podstawowymi informacjami o niej zawsze są umieszczane w bloku div z nazwą klasy "span-6". To sugerowało, że blok div ma nazwę klasy "span-6" jeśli i tylko jeśli ten blok opisuje opublikowany artykuł. Aby to wstępnie potwierdzić, sprawdziłem nazwę klasy innego, losowo wybranego divu na stronie głównej. Trafiłem na "span-3" (chociaż w trakcie pisania tego wpisu znalazłem też klasę "span-8", więc "span-3" nie jest jedyną stosowaną opcją na DP). To pozwoliło mi założyć, że twierdzenie o nazwie klasy "span-6" jest prawdziwe, lecz konieczne było też ostateczne potwierdzenie tego w testach skryptu, który miałem zamiar stworzyć.
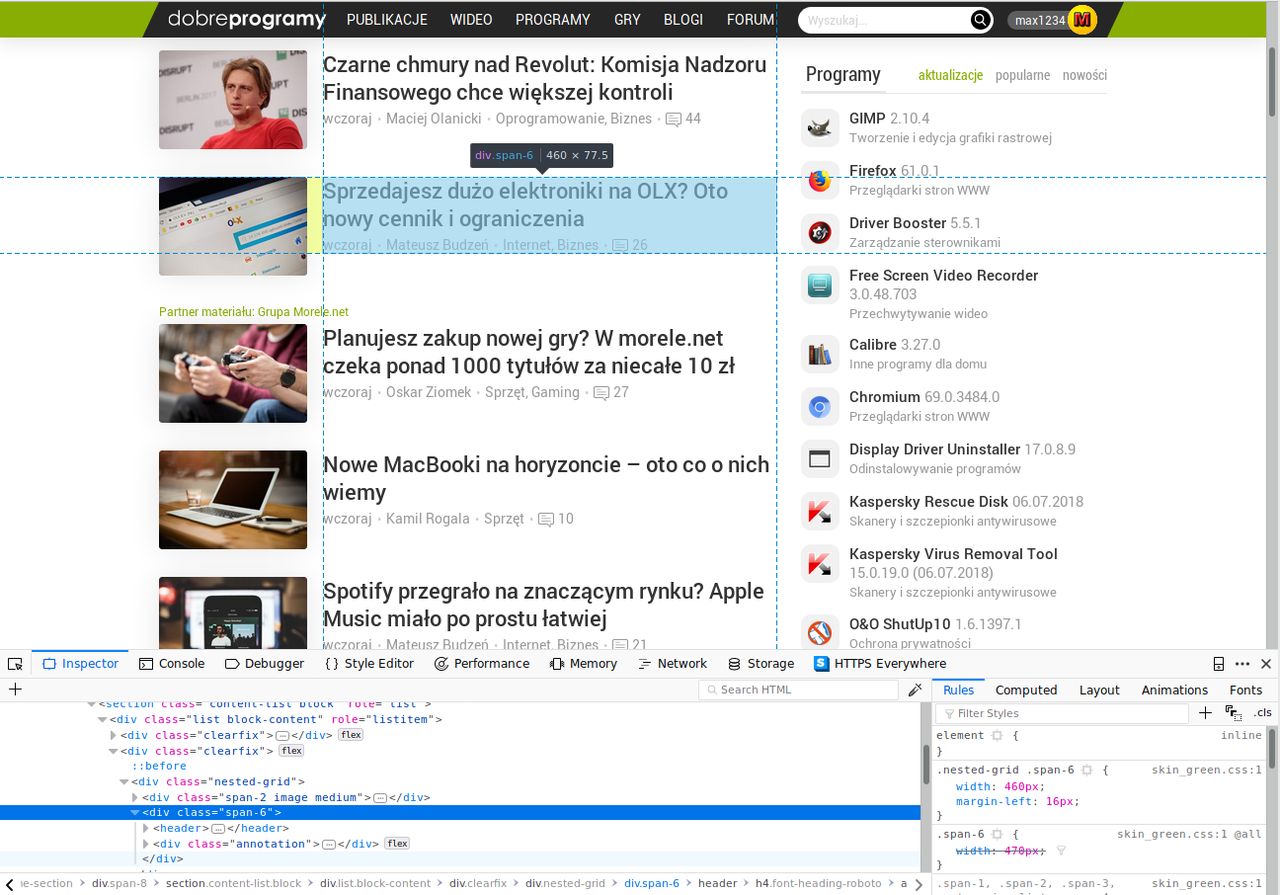
Po ustaleniu, jak reprezentowana jest część opisująca publikację, musiałem zmierzyć się z wyzwaniem przeanalizowania strony z treścią artykułu. Chciałem, aby wyświetlana zajawka miała 40 słów lub długość równą długości pierwszego akapitu, w zależności od tego, co jest krótsze. Z tego względu trzeba było znaleźć metodę na bezproblemowe zlokalizowanie pierwszego akapitu publikacji. Tutaj również z pomocą przyszedł inspektor DOM.
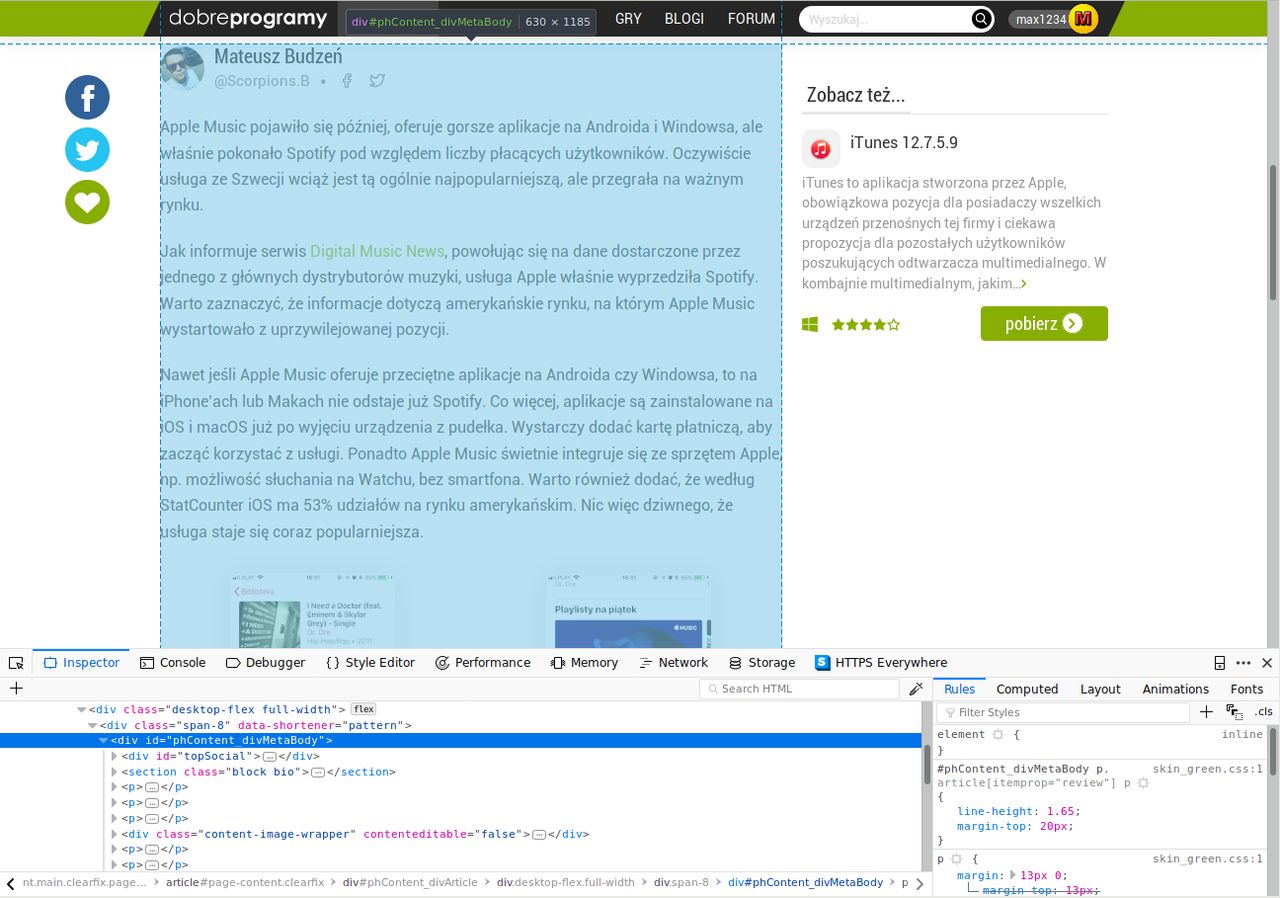
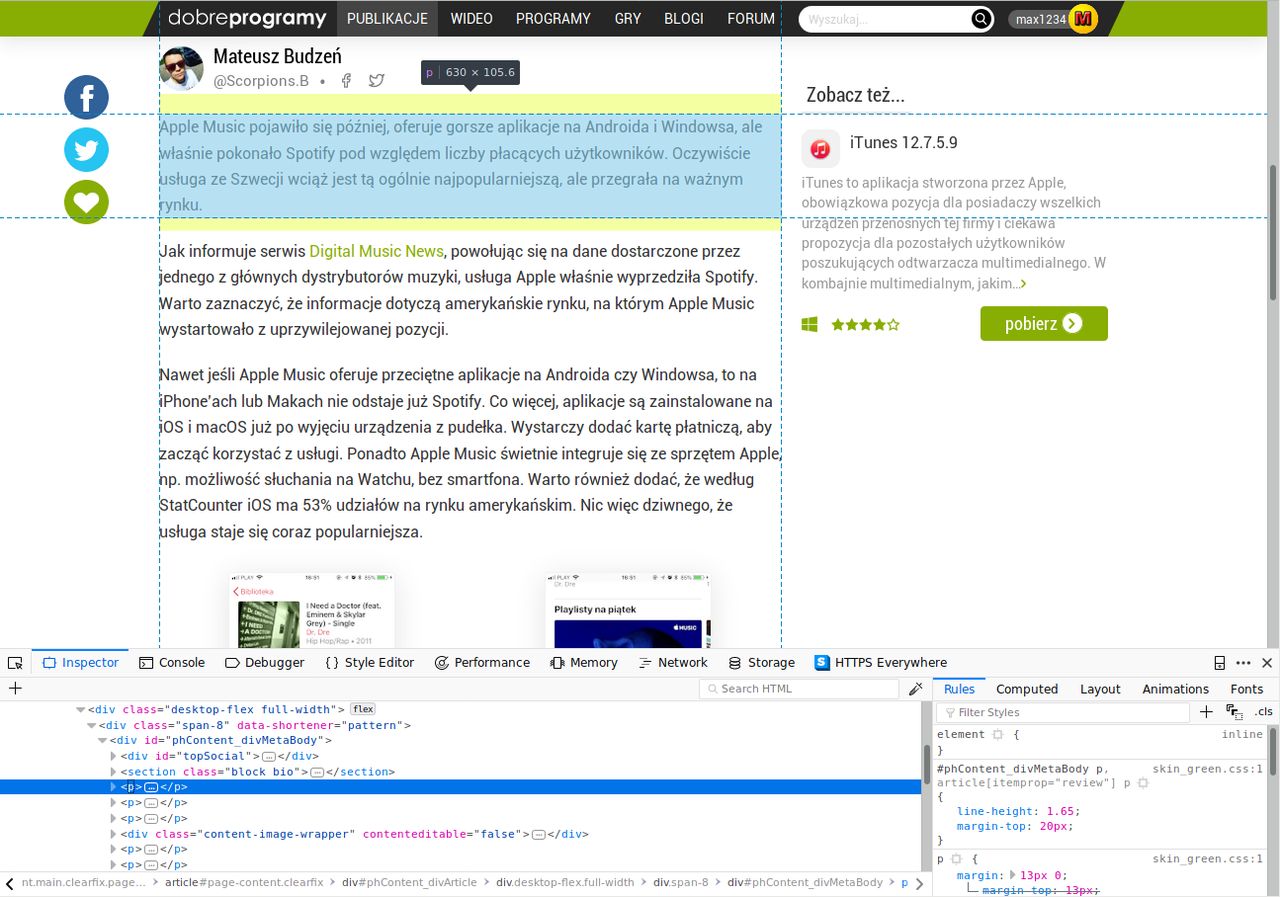
Analiza pierwszego artykułu pozwoliła z pełną stanowczością stwierdzić, że konkretna treść znajduje się w bloku div z identyfikatorem "phContent_divMetaBody". Ponadto zauważyłem, że każdy akapit właściwej publikacji zawarty jest w tagach p bez jakichkolwiek klas ani identyfikatorów. Dla pewności otworzyłem i przeanalizowałem strukturę drugiego artykułu, który zawierał aktualizację w szarym bloku, jak niżej:
Okazało się, że dokładane akapity stanowiące aktualizację, a nie właściwą część publikacji, są zamknięte w tagach p z nazwą klasy "text-frame". Właściwe akapity wciąż mają tagi p bez żadnych klas i identyfikatorów. To sugerowało, że pierwszy konkretny akapit do wyświetlenia w całości lub częściowo jako zajawka znajduje się w pierwszym wystąpieniu elementu p w bloku div o identyfikatorze "phContent_divMetaBody".

Pozostawało tylko pytanie, co z publikacjami blogowymi, które również są linkowane na stronie głównej. Rzut oka na stronę blogową rozwiał wszystkie wątpliwości.
Treść wpisu znajduje się w bloku div o nazwie klasy "entry-content" i zawartym w sekcji article, a akapity kodowane są tak samo, jak w artykule redakcyjnym.
Z tą wiedzą zacząłem myśleć o tym, jak wyświetlać zajawki. Sposób na to okazał się stosunkowo prosty:
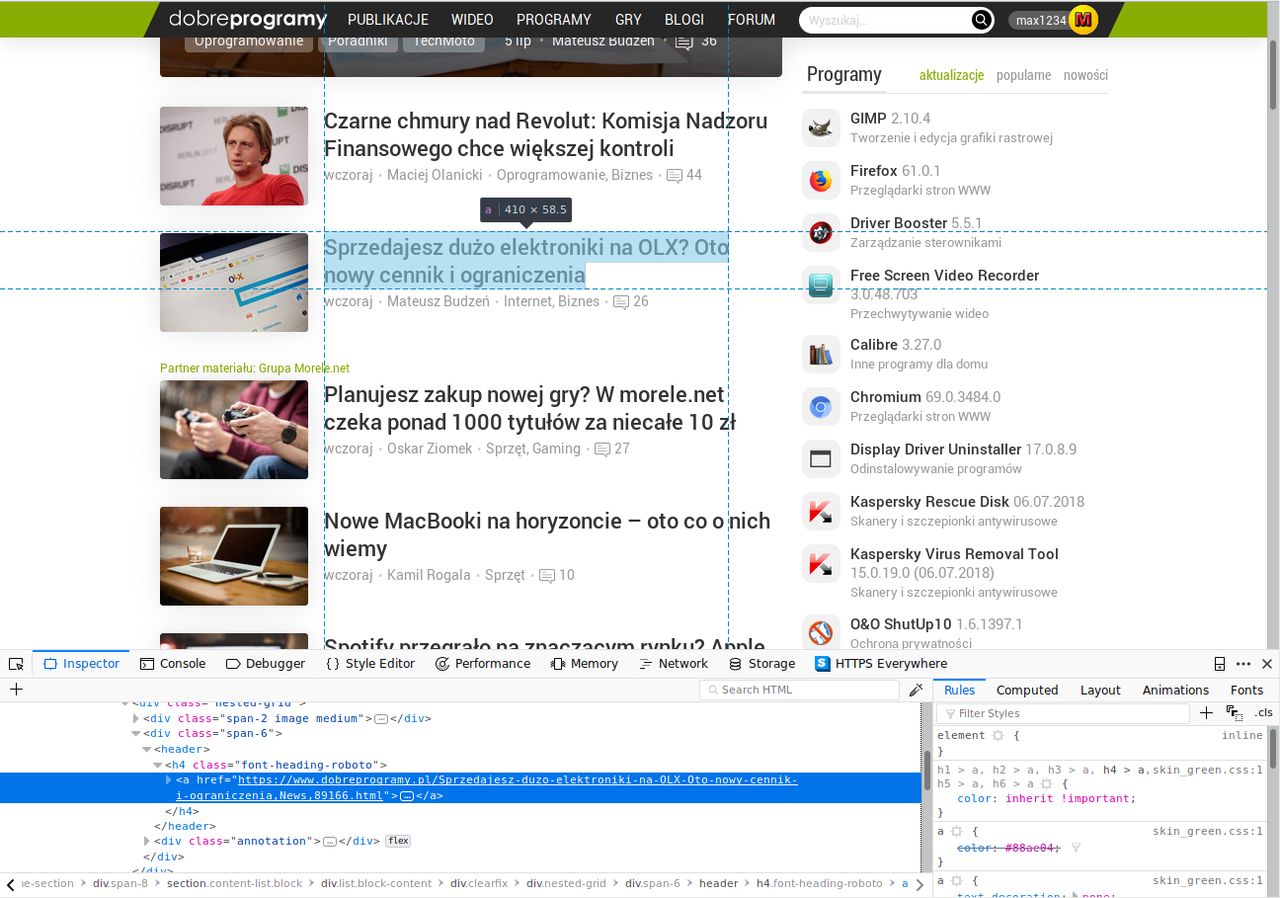
- Dla każdego bloku div z nazwą klasy "span-6" należy pobrać link do artykułu, wykorzystując pierwsze wystąpienie elementu a w sekcji header zawartej w bloku div o nazwie klasy "span-6" (jak na powyższej ilustracji).
- Wykorzystując XHR (powszechnie stosowany w AJAX), należy pobrać kod strony z artykułem dostępnej pod linkiem zdobytym w kroku pierwszym.
- Kod pobranej strony należy przetworzyć z wykorzystaniem parsera DOM dostępnego w JavaScripcie, aby otrzymać treść pierwszego akapitu artykułu, znając jego dwie możliwe lokalizacje. Najpierw należy sprawdzić pozycję dla publikacji redakcyjnej (w bloku div o identyfikatorze "phContent_divMetaBody"), a w przypadku problemów sprawdzić pozycję dla wpisu blogowego (w bloku div o nazwie klasy "entry-content").
- Należy policzyć liczbę słów w zdobytym akapicie. Jeżeli jest ona mniejsza niż lub równa 40, należy wyświetlić cały akapit pod tytułem artykułu. W przeciwnym razie należy zliczyć pierwsze 40 słów, które utworzą zajawkę do pokazania.
- Początkowy fragment należy wstawić do elementu p, który następnie należy dodać do bloku div o nazwie klasy "span-6".
Założyłem, że powyższa metoda zadziała nie tylko na stronie głównej, ale też na każdej stronie z listą publikacji. Z racji tego, że nie sprawdzałem struktury jakiejkolwiek strony z listą publikacji innej niż strona główna, to założenie musiałem sprawdzić już w testach stworzonego kodu.
Napisanie skryptu zajęło mi godzinę. Korzystałem z czystego JavaScriptu. Po stworzeniu kodu przeprowadziłem testy w Firefoksie 61 z Greasemonkey i Chromie 67 z Tampermonkey, zarówno na wersji DP dla komputerów (tryb dzienny i nocny), jak i wersji mobilnej (tryb dzienny). Zajawki były wstawiane poprawnie we właściwych miejscach na stronie głównej, a także na wszystkich stronach z listą publikacji. Zaliczone testy potwierdziły wszystkie moje przypuszczenia, które były wcześniej tylko założone lub wstępnie zweryfikowane.
Kod źródłowy
AKTUALIZACJA: Skrypt dostępny jest też na OpenUserJS. Ponadto lekko zmieniony został link do kodu źródłowego na GitHubie.
Pełny kod źródłowy skryptu jest opublikowany na licencji GNU GPL v3.0 na moim koncie GitHub.
O ile dla mnie fragment o maksymalnej długości 40 słów jest wystarczający, dla niektórych może to być nieodpowiednie ustawienie. Z tego powodu po napisaniu całego kodu wydzieliłem wartość liczbową 40 do stałej MAX_NUMBER_OF_WORDS. Dzięki temu możliwa jest łatwa zmiana maksymalnej liczby słów do pokazania w zajawce artykułu: wystarczy zmienić wartość opisanej stałej znajdującej się na początku kodu.
Skrypt opiera się na konkretnych nazwach klas i identyfikatorów używanych w kodzie stron DP. Jakakolwiek zmiana, nawet kosmetyczna, przez administrację może spowodować, że przestanie on poprawnie działać.
![Stabilizacja w kamerach Sony może być jeszcze lepsza. Catalyst Browse [Recenzja]](https://v.wpimg.pl/Nzk3ZC5wYRsKUSxwGgxsDkkJeCpcVWJYHhFgYRpBegJdB3U3UBQmVBxDOSdbWT4WRFo3JBoUL0wIUG5zBlorTFsFd3cAEn5XUgZiJhgSKhtfVj5wAUB3TQ8dKi1SVTM)


![Survival looter-shooter nareszcie PC, ale we wczesnym dostępie. Vigor [Recenzja]](https://v.wpimg.pl/MDJlOC5qYiUrDjlwGgpvMGhWbSpcU2FmP051YRpHeTx8WGA3UBIlaj0cLCdbXz0oZQUiJBoVK3F7W3wmUVwpJyhYYndUSCtpK15_JRhEfHR_XXl2B0F_IXJCJTNSUzA)



![Mobilny czytnik, który mógłby zostać smartfonem. Onyx Boox Palma [Recenzja]](https://v.wpimg.pl/YzA5Yi5qdhsgVy9aGgp7DmMPewBcU3VYNBdjSxpHbQJ3AXYdUBIxVDZFOg1bXykWblw0DhpAP05xVmBaV1xhGCMBdF1QEzpXIAJoCBhCbU54AWlfBxJpQyMbMxlSUyQ)