

O (pseudo)losowości, ludziach i innych zjawiskach przyrodniczych

Mały eksperyment. Podaj szybko 3 liczby losowe w zakresie od 1 do 10.
Zrób to zanim przejdziesz dalej proszę. To nie zaboli i nie będzie totalnie głupie.

Nie, nie wpisuj w komentarzu. Potrzebne nam to jest do pewnych obserwacji. Śmiało możesz też spytać kilku innych osób i zobaczyć efekty.
To tylko prosty eksperyment, ale być może już uda nam się coś zaobserwować.
Mamy to?
Prawdopodobieństwo że podałeś 1, 1 , 1 jest dokładnie takie samo jak każdej innej sekwencji, natomiast zazwyczaj liczby w tym eksperymencie w ogóle się nie powtarzają. Czego to dowodzi?
Na tym etapie absolutnie niczego, bo mogliśmy nie trafić oczywiście na taki przypadek. Absolutnie normalne. Jednak według badań, ludzie mimo wszystko mają pewna dozę "nielosowości", która objawia się przy generowaniu dłuższych ciągów znaków.
U każdego to działa nieco inaczej, ale nieświadomy proces myślowy mógłby na przykład wyglądać tak:
Hmmm... 1 i 10 nie – bo są na krańcach. Liczby parzyste raczej nie, bo jakoś tak głupio. To może 3, 5 i 7?
Zgadłem? Pewnie w jakimś przypadku tak, ale znów niczego to nie dowodzi.
Jednak przy dłuższych ciągach, generowanych przez ludzi, znając poprzednie wyniki, teoretycznie można z większym prawdopodobieństwem odgadnąć następną liczbę. Pojawiają się schematy... Być może związane z naszymi preferencjami, sposobem myślenia, może nastrojem - dziś jeszcze dokładnie nie wiemy, co na to wpływa.
Skupmy się jednak na naszym postrzeganiu liczb losowych. Gdyby ktoś powiedział 1, 1, 1 instynktownie zarzucilibyśmy mu, że nie są to liczby losowe. A przecież mogły by takie być.

Losowość jest nieintuicyjna dla nas.
Rozkład losowych punktów w przestrzeni może wyglądać tak:

Lub tak:

Jednak, dla nas, tak podskórnie, pierwszy obraz jest jakby bardziej wiarygodny.
Generowanie liczb losowych na komputerach to również spory problem. Program generalnie nie jest w stanie wygenerować w pełni losowych liczb z niczego. Nie da się zapisać algorytmu, który by to robił. Z samej definicji, jeśli istnieje algorytm, to nie jest to losowość. Dlatego stosuje się tu pewne triki, o których teraz porozmawiamy.
Jedną z metod generowania liczb losowych jest metoda Von Neumana, którą najprościej można zademonstrować tak:
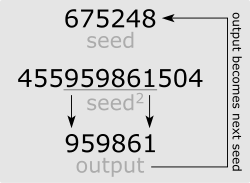
Jak łatwo zwrócić uwagę, wykorzystano tu jakąś liczbę początkową, czyli tak zwane ziarno. Takie generowanie liczb losowych ma swoje niezaprzeczalne zalety.
Na przykład, jeśli chcemy przeprowadzić symulację lotu rakiety z losowymi danymi, wymyślamy ziarno i przeprowadzamy eksperyment. Następnie modyfikujemy eksperyment i chcielibyśmy przeprowadzić go w „tych samych losowych warunkach”. To co musimy zrobić, to podać to samo ziarno i gotowe. To nie jest przykład oderwany od rzeczywistości. Liczby losowe i metoda Monte Carlo, o której za chwilę, były na przykład wykorzystywane przy misji Apollo:

Znając ziarno możemy wygenerować sekwencję liczb powtórnie. Nie ma konieczności zapamiętywania całej sekwencji, która może być ogromna. Program zachowuje się deterministycznie.
Ogromna zaleta. Prawda?
Łatwo możemy to zbadać empirycznie:
import random; random.seed(10) print(random.randrange(100)) #możesz przetestować ten kod na przykład tu: #https://repl.it/languages/python3
Tu akurat mogę przewidzieć wynik – jest to 73.
Gdyby wyrzucić drugą linijkę, otrzymamy za każdym razem inny wynik (który odgadnie tylko wróżbita Maciej).
Należy zwrócić uwagę, że w implementacji generatora liczb pseudo losowych w tym wypadku, ziarno domyślnie jest generowane, prawdopodobnie na podstawie czasu systemowego.
W języku Go na przykład, nie dzieje się to z automatu:
package main import ( "fmt" "math/rand" ) func main() { fmt.Print(rand.Intn(100), ",") fmt.Print(rand.Intn(100), ",") fmt.Print(rand.Intn(100), ",") } //Możesz przetestować ten kod na przykład tu: //https://play.golang.org
Wynik?
81,87,47
Za każdym razem, gdyż ziarno jest takie samo.
Czasem zdarza się również błędna implementacja generatora liczb losowych. Oto graficzna reprezentacja starego już algorytmu z języka PHP.

Na tej grafice widać, że generator ma tendencje to tworzenia schematów i skupisk.
Tak powinno to wyglądać (mniej więcej):

A jakie to ma znaczenie? Gdybyśmy tworzyli grę „odgadnij liczbę od 0 do 100” to pewnie znikome. Jednak w przypadku wykorzystywania liczb pseudolosowych do kryptografii, taki stan rzeczy stanowi ogromne ryzyko.
Niezaprzeczalną zaletą algorytmów do generowania liczb pseudolosowych jest ich prędkość, czy też „złożoność obliczeniowa”.
Ponieważ jesteśmy w stanie szybko generować liczby losowe, możemy wykorzystać ten fakt w optymalizacjach, gdzie nie zależy nam często na 100% pewności wyniku.
Na przykład w grach, przy badaniu kolizji obiektów, zamiast sprawdzać kolizje dla każdego punktu, moglibyśmy wykorzystać losowość i określać że na powiedzmy: na 80% nie nastąpiła kolizja.
W tym celu moglibyśmy losować punkty w każdym przebiegu głównej pętli, i sprawdzać tylko te wylosowane.
Ponieważ współczynnik prawdopodobieństwa jest wysoki, a powtarzamy obliczenia przy każdym przebiegu, to najgorszym co się ma prawo wydarzyć, to to, że o kolizji dowiemy się kilka przebiegów później.
To taki prosty, wymyślony przykład, ale pozwala w miarę zrozumieć koncepcję.
W tym miejscu należy wprowadzić i wyjaśnić metodę Monte Carlo.
Wikipedia podaje taki "życiowy przykład" w tym temacie:
Typowym przykładem może być modelowanie wyniku zderzenia cząstki o wysokiej energii z jądrem złożonym, gdzie każdy akt zderzenia elementarnego (z pojedynczym nukleonem jądra) modelowany jest oddzielnie poprzez losowanie liczby, rodzaju, kąta emisji, energii itp. cząstek wtórnych emitowanych w wyniku takiego zderzenia.
Nie wiem, czy to możliwe, ale postaram się przybliżyć metodę "jeszcze prościej". Empirycznie.
Przeprowadzimy podobny eksperyment! Nie zbyt skomplikowany.
Będziemy obliczać pole powierzchni rysunku jakiegoś obiektu. Każdy punkt, może znajdować się albo w obrębie obiektu, albo poza nim. W naszym wypadku obiektem będzie kot. Wyliczymy później stosunek wszystkich punktów do punktów w obrębie obiektu, aby oszacować powierzchnię.
Oto schemat naszego eksperymentu:

Aby uprościć zadanie, będziemy wyliczać wszystko na podstawie koloru badanego punktu. Piksel biały, i piksel "nie biały" - w ten sposób algorytm znacznie się uprości. Najpierw jednak potrzebujemy naszego modelowego rysunku. Wykonałem taki oto:

Podobny. Prawda?
Przeprowadźmy więc obliczenia w sposób tradycyjny, czyli sprawdzając punkt, po punkcie kolor.
W tym celu stworzyłem prosty program w języku Python:
from PIL import Image im = Image.open('image.bmp') pix = im.load() count = 0 print(im.size) for x in range(0, im.size[0]): for y in range(0, im.size[1]): if pix[x,y] != (255,255,255): count+=1 print(count) # WYNIK DOKŁADNY print(count / (im.size[0] * im.size[1])) # wynik: #(320, 200) #11402 #0.17815625
Ok. Mamy naszą deterministyczną odpowiedź. Prawie 18% obrazka zajmuje czarny kot. Warto zwrócić uwagę, że porównanie zawarte w programie wykonało się dokładnie 64 000 razy (obrazek ma 320x200 pikseli), zanim uzyskaliśmy ten wynik.
Przejdźmy zatem do drugiej metody, w której będziemy losować punkty, a następnie wyliczymy stosunek ilości punktów czarnych, do ilości podjętych prób.
W tym celu również stworzyłem mały program:
from PIL import Image import random import sys repeats = int(sys.argv[1]) im = Image.open('image.bmp') pix = im.load() count = 0 print(im.size) def aprox_size(height, width, number_of_repeats): black = 0; for count in range(number_of_repeats): x = random.randrange(height) y = random.randrange(width) if pix[x,y] != (255,255,255): black+=1 return black/number_of_repeats for x in range(20): percent = aprox_size(im.size[0], im.size[1] , repeats) print(percent)
W ten sposób zobaczymy 20 wyników działania funkcji, z określoną ilością losowanych punktów.
Plik odpalamy komendą:
python3 motecarlo2.py _ilość_punktów_
Za każdym razem oczywiście będziemy mieli inne wyniki, ale dzięki modyfikacji ilości punktów myślę że uda nam się już coś zaobserwować.
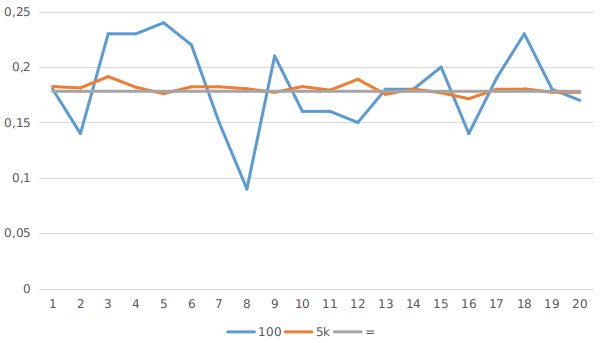
Przykład działania dla 100 punktów:
python3 montecarlo2.py 100 0.18 0.14 0.23 0.23 0.24 0.22 0.15 0.09 0.21 0.16 0.16 0.15 0.18 0.18 0.2 0.14 0.19 0.23 0.18 0.17
Wyniki są bardzo rozrzucone. Trafiła nam się nawet wartość 0.09 a maksimum wynosi 0.24. W tym czasie jednak, w jednym przebiegu funkcji wykonaliśmy zaledwie 100, zamiast 64 000 porównań.
Zwiększmy zatem ilość powtórzeń:
python3 montecarlo2.py 5000 0.1824 0.1812 0.1914 0.1818 0.176 0.1822 0.1822 0.1804 0.1772 0.1824 0.1792 0.189 0.1754 0.1802 0.1768 0.1714 0.18 0.1804 0.1772 0.1772
Wartości oscylują już całkiem nieźle koło naszej wartości prawdziwej. Zdarzają się odchyły, ale ogólnie wynik jest zadowalający dla niektórych zastosowań. A ilość porównań w jednym przebiegu to 5 000.
Wizualizacja wyników:
Co się stanie jeśli będziemy mieli 64 000 losowych powtórzeń?
Zostawiam to ciekawskim.
Aby sprawdzić ten kod u siebie potrzebujesz Pythona 3 i obrazka, ale serdecznie zachęcam do poeksperymentowania.
Podobne zabiegi wykorzystuje się na przykład w ray tracingu (metoda śledzenia promieni w grach), gdzie nie jesteśmy w stanie obliczyć wektorów wszystkich padających promieni.
Losowość ogólnie ma też taką cechę, że prawdopodobieństwo wystąpienia sekwencji zwiększa się wraz z ilością prób. Znamy to wszyscy z matematyki, ale nadal wydaje się to czasem nieintuicyjne.
Prawdopodobieństwo wypadnięcia liczb 1,2,3, 4, 5, 6 w dużym lotku jest takie samo jak każdych innych liczb. Jeśli Totalizator sportowy będzie działał dostatecznie długo to takie liczby kiedyś zapewne padną.
Ba… Jeśli totalizator sportowy działałby w nieskończoność, to wypadnięcie 1,2,3,4,5 i 6 jest pewne.
Jeśli będziemy losować ciągli znaków, to kiedyś otrzymamy na przykład pełne zdanie "super wpis o liczbach losowych". Po prostu musimy długo losować.
Jeśli uda nam się ustalić algorytm generowania liczb pseudolosowych, i poznać na przykład czas ("timestamp") przyjęty do ziarna, a teoretycznie jest to wykonalne, liczby przestaną być dla nas losowe. W obawie przed tego typu atakami, specjaliści wybierają metody tworzenia liczb losowych, opierające się o zjawiska fizyczne.

Firma CloudFlare, zajmująca się bezpieczeństwem, generuje na przykład liczby losowe wykorzystując lampy lawowe, okraszone oczywiście dodatkowymi algorytmami. Dzięki temu osiągamy pełną losowość i liczby są dla nas mocno niedeterministyczne.
Innym sposobem generowania takich liczb jest szum atmosferyczny, na który wpływa tak wiele czynników, że na dzień dzisiejszy nie jesteśmy w stanie go przewidzieć.
Upraszczając, można powiedzieć, że liczbą losową jest coś, czego nie możemy przewidzieć. Kiedyś ludzkość nie potrafiła przewidzieć zaćmienia księżyca. Gdyby więc tworzyć liczby losowe na tej podstawie, do pewnego momentu byłyby dla nas liczbami losowymi. Gdy odkryjemy "jak to działa", liczby losowe stają się dla nas przewidywalne,czyli deterministyczne. Podobnie jest z innymi zjawiskami.

Jeśli nasze super szybkie i dokładne mierniki wraz z super szybkimi komputerami będą w stanie przewidzieć szum atmosferyczny, to i ta metoda straci rację bytu.
W pewnym momencie, możemy dojść do poziomu “demona Laplace’a” (https://pl.wikipedia.org/wiki/Demon_Laplace’a).
Na szczęście póki co, świat deterministyczny nie jest i nie możemy przewidzieć wszystkiego. Fizyka kwantowa i zasada nieoznaczoności też “napawa optymizmem” w tym zakresie.
Wróćmy na chwilę jednak do początku artykułu.
Jeszcze jeden eksperyment. Masz przed sobą rozpoczęty obraz z losowymi kropkami.

Dotknij miejsca gdzie postawiłbyś następną losową kropkę.
Czy było to w pełni losowe, czy jednak zasugerowałeś się drogi czytelniku poprzednimi kropkami? Widzisz tą pułapkę na obrazku prawda? Dałeś się złapać, czy świadomie uniknąłeś wyboru białej przestrzeni? W obu wypadkach... był to wybór losowy?
Weźmy zatem głęboki oddech odetchnijmy chwilę i zadajmy sobie kilka pytań:
Czy my, jako ludzie w ogóle potrafimy generować liczby prawdziwie losowe?
A jeśli nie, to czym różnimy się od komputera?
Czy super sztuczna inteligencja nie miałaby przypadkiem tak samo jak my?
"djsuhf dsof[ dfosof " - czy jest to losowy ciąg znaków?
Udowodnij...

Serdecznie dziękuję Radkowi,(https://www.linkedin.com/in/radoslaw-zagrobelny/) bez którego ten wpis by nie powstał. To jego pasja i świetne wystąpienie "Jak brzmi szum atmosferyczny", jak również materiały z tej prezentacji pozwoliły na stworzenie tej małej zajawki.
Liczby losowe i pseudo losowość to szalenie szeroki temat. To, na czym skupiałem się dziś, to nasze postrzeganie tego tematu.
Mam nadzieję, że temat was zainteresował. Po więcej odsyłam już do https://www.random.org
O samej „losowości generowanej przez ludzi” można znaleźć sporo materiałów, bo to arcyciekawy temat. Tu ktoś wrzucił troszkę o zagadnieniu wraz z linkami do literatury:
https://psychology.stackexchange.com/questions/3591/how-well-can-a-hum...

![Survival looter-shooter nareszcie PC, ale we wczesnym dostępie. Vigor [Recenzja]](https://v.wpimg.pl/MmU4LmpwYgw0VjpeXwxvGXcObgQZVWFPIBZ2T19CdFotB31bXwMoDj0aOx0TEyNDJVhjBB0QYgkzAX1aQxIpQDFXLlldQyxUMxktX0ARYFhkBHlcRkJ_XWdRdEMaBypPKA)




![Wciąga jak anomalia i pozostawia blizny. S.T.A.L.K.E.R. 2 [Recenzja]](https://v.wpimg.pl/YWQ1LnBudjYwUzpdbQ57I3MLbgcrV3V1JBN2TG1AYGApAn1YbQE8NDkfOx4hETd5IV1jBy8SdmBlUntYckE9ejQHfAtvQWFhYxx1XnAUdGVlBS5ddxNuNDBVeUAyGz51LA)
