

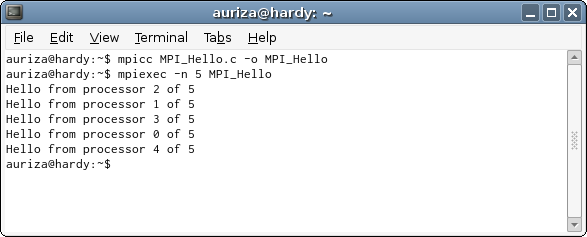
Ciąg dalszy wdrażania Red Hatów — czyli o tym, jak nic nigdy nie działa tak, jak byśmy chcieli
Jakiś czas temu pisałem o wdrażaniu Red Hatów, a właściwie Fedory 21, na dużej liczbie komputerów (około 180). Ten pozornie bezbolesny i bardzo dobrze udokumentowany proces, okazał się być generatorem nieprzewidywalnych problemów, na które można natknąć się wyłącznie przez praktykę: żadną miarą nie dałoby się wydobyć ich z dokumentacji, ani zabezpieczyć przed takimi scenariuszami bez doświadczenia.
W końcu jednak udało się, rzutem na taśmę, w ostatniej chwili. Sam byłem zaskoczony efektem, wybrałem bowiem Fedorę 21, a był to system w wersji beta. Prace nad wdrożeniem Fedory rozpocząłem z początkiem listopada 2014, kiedy to F21 miała być już wydana… gdyby nie pięciokrotne opóźnienia i przeniesienie premiery na połowę grudnia. Niezłomnie jednak pracowałem na wersji 21 Beta, na tyle nowej, że instalator nienadzorowany „nie znał samego siebie” i najnowszą obsługiwaną wersją było wydanie f20. Na szczęście generowało to jedynie ostrzeżenia, a nie błędy i instalator okazał się w pełni zgodny z systemem z przyszłości. Swoją drogą nigdy tego nie poprawiono: aż do końca wsparcia dla systemu Fedora 21, menedżer instalatorów zdalnych dzielnie twierdził, że profil f21 jest „nieznany”.
Pomarudźmy trochę
Istnienie takiego projektu, jak CentOS czy Scientific Linux świadczy o tym, że istnieje zapotrzebowanie na stabilnego, „korporacyjnego” Linuksa poza wielkimi firmami, które mogą sobie kupić prawdziwego Red Hata. Dotychczas chciałem myśleniem życzeniowym zakrzyczeć ten fakt, głównie ze względu na moją nienawiść względem forków. Dlatego też nienawidzę Scientific Linuksa i Linux Minta, z trudem znoszę nawet Ubuntu, a wszelkich pozostałych wynalazków nawet nie dotykam. Dogmatycznie twierdzę, że poza Fedorą i Debianem świat naprawdę nie potrzebuje nic więcej. Musiałem jednak zrewidować swój pogląd na temat CentOSa (cóż za paskudna nazwa!!), ponieważ Fedora osiągała poziom sprawności, który można opisać słowami „działa, ale”. Wytrzymała rok, owszem, z tym, że od czasu do czasu pojawiały się tzw. Drobne Trudności™, które w ogóle nie miały racji bytu. Przejście na CentOSa i wykorzystanie w tym celu usługi Hyper-V ukazało jednak, że nigdy nic nie działa, jak należy. Nie da się nawet znaleźć winnego, bowiem problemy są na tyle rozproszone, że w zasadzie winni są wszędzie, a ściślej winna jest ludzka natura. Co więcej, problemy nie dotyczą samego Linuksa: Hyper-V potrafił odstawić takie numery podczas konfiguracji, że aż dziw brało, jakim cudem ten system kosztuje tyle, co mały samochód. Ja oczywiście opiszę, o co mi chodzi tym razem, ale najpierw trochę ponarzekam.

Krótko mówiąc, nic nigdy nie działa. Nigdzie. Morałem, który każdy, kto pracuje w „modern IT” (a więc nie reinstalowanie XP z płyt i konserwacja Acer TraveMate’ów na Core 2 Duo, tylko kontakt z technologią mniej więcej aktualną) powinien wyciągnąć po dłużej przeprawie z rzekomo bezawaryjnymi rozwiązaniami, jest stwierdzenie, że wszystko wokół działa przez przypadek i ogólnoświatowa, unieruchamiająca katastrofa informatyczna powinna się wydarzyć już dawno, i to wiele razy. Czasem ma się wręcz wrażenie, że los drwi sobie z nas, szczególnie, gdy wypowiadając słowa „jakim cudem udało mi się zdalnie zalogo…” połączenie zrywa się, nie chcąc wstać z powrotem. Szereg podobnych wydarzeń przypomina kreskówki ze Strusiem Pędziwiatrem, w których to Kojot spada w przepaść, dopiero, gdy uświadomi sobie, że stoi w powietrzu. Obsługa rzekomo homogenicznej sieci opartej na jednym systemie obfituje również w przygody, które zupełnie przeczą logice: jeden z trzydziestu komputerów otrzymuje inną konfigurację, niż reszta, albo nie potrafi uruchomić instalatora sieciowego, zgłaszając absurdalne błędy, opisywane w Internecie słowami „nie wiemy, dlaczego tak się czasem dzieje” (poważnie: CLOSED CANTFIX ). Przestałem się jednak przejmować pojedynczymi komputerami. Jak to mówił Alexander Pierce : „I don’t care about one ship, I care about the fleet”. Obecnie już się z tym zgadzam.

Nie patrz, bo się zepsuje!
Wróćmy jednak do Fedory – cóż takiego może się samoistnie popsuć? Fakt, rozum nakazuje, że nic. Informatyka użytkowa nie jest jednak najwyraźniej nauką ścisłą i teoria potrafi naprawdę urokliwie mijać się z praktyką. Pierwsza rzecz wyszła na jaw bardzo szybko.
Sterowniki graficzne
Przypomnę, że w laboratoriach musi być dostępne CUDA/OpenCL. Sieć jest wykorzystywana do obliczeń typu HPC i z tego powodu wymaga własnościowych sterowników do karty graficznej, bo na Intelu liczyć owszem można, ale niewiele ma to sensu. Własnościowy sterownik NVidia jest naturalnie niedostępny w repozytorium Fedory, ale od czego jest RPMFusion? Otóż jest to rozwiązanie, które działa jedynie w teorii. Co więcej – zazwyczaj działa na większości sprzętu „zwykłych użytkowników”. Niestety przestaje działać na skalę masową, zwłaszcza, jak jest mało czasu. Na czym polega problem? Otóż repozytorium ze sterownikiem „rozjeżdża się” numerami wersji z repozytorium systemowym. Następuje wtedy osobliwa forma wyścigu: RPMFusion zawiera sterownik za stary dla systemu, który właśnie pociągnął aktualizacje. Nie mogę zatem dokonać synchronizacji lokalnych repozytoriów, bo istnieje wysoka szansa, że „rpmfusion” będzie zawierać sterowniki dla starszego jądra, niż to w „updates”. Instalator yum rzekomo potrafi rozwiązywać takie konflikty, ale jeszcze nigdy się to nie udało. Wielki wyścig przybierał czasem zabawne formy: gdy udało mi się dopaść repozytoria na wspólnej wersji, wyszedłem do łazienki, po czym wróciłem… i wersje były już inne. Byłem na siebie bardzo zły, że nie puściłem synchronizacji 5 minut wcześniej. Jakim cudem działa to zwykłym użytkownikom? Otóż nigdy nie instalują oni sterowników do karty graficznej równolegle z systemem. Robią to później. I gdy jakieś wersje nie pasują, instalator po prostu poczeka z aktualizacjami i zainstaluje je, gdy zależności zostaną spełnione. Ale weźmie starszą wersję. Ale ja nie mogę trzymać u siebie miliona wstecznych wersji każdego pakietu. W efekcie musiałem użyć lokalnego repozytorium zrobionego „na chama” poprzez skopiowanie gałęzi instalacyjnej z serwera zwierciadlanego i wykorzystać wersje sterownika, które pasują do tej konkretnej jednej wersji akurat dla tych pakietów. Na stacjach, na których występował ten problem, musiałem wstrzymać aktualizacje. Trudno. Warto też zwrócić uwagę na to, że im dalej od premiery systemu, tym dłużej trwają rozjazdy wersji jądra w RPMFusion. Może więc warto zaktualizować Fedorę do wersji 22? Niestety nie – kończy się to katastrofą, ale o tym za chwilę.
OpenMPI
Drugim problemem był OpenMPI. To niepotrzebnie skomplikowane środowisko wymaga prawidłowej konfiguracji kluczy SSH, aby program mógł się w przezroczysty sposób wykonywać na kilku maszynach, komunikując się właśnie przez SSH, bez pytania o hasło. W normalnym świecie wystarczyłoby po prostu założyć poprawne klucze. Niestety studenci piątego roku informatyki nie potrafią tego zrobić, mimo łopatologicznych instrukcji i konieczne było założenie konta bez powłoki, tylko na potrzeby MPI, gdzie po prostu nie ma hasła, więc nie trzeba generować kluczy. Takie rozwiązanie przeszło testy, ale oczywiście przestało działać jeden dzień przed zajęciami, na których wreszcie MPI było potrzebne. Właśnie tutaj wystąpiło wspomniane już zjawisko Strusia Pędziwiatra: dotychczasowa konfiguracja OpenMPI nigdy nie miała prawa działać, ale popsuła się dopiero wtedy, gdy ktoś to zauważył. Problemem był drugi interfejs sieciowy. Komputery w laboratorium HPC zgłaszają cztery interfejsy (tak mówi ifconfig): dwie fizyczne karty sieciowe (w tym jedną online) o kosmicznych nazwach, bo eth0, eth1 itp. było zbyt proste, interfejs sprzężenia zwrotnego (lo, od loopback) oraz nieszczęsny virbr0. Ten ostatni powinien być znany fanom wirtualizacji. Jest to bowiem nic innego, jak wirtualny przełącznik, pozwalający na połączenia mostkowe między kontenerami systemów zwirtualizowanych. Wadą tego, skądinąd genialnego, rozwiązania jest fakt, że interfejs virbr0 jest online nawet wtedy, gdy nie są obecne żadne maszyny wirtualne. Ale OpenMPI o tym nie wie. Dlatego, gdy widzi podniesiony interfejs sieciowy, usiłuje go użyć. Kończy się to w najgorszy możliwy sposób, jakim jest oczekiwanie na timeout. Co więcej, tylko około raz na 20 prób pojawia się komunikat tłumaczący, gdzie tak naprawdę jest problem. Krótka wizyta u wujka Google’a pozwala nam dowiedzieć się, że interfejs virbr0 nigdy nie dogada się z OpenMPI i należy wykluczyć go ze zbioru urządzeń wykorzystywanych w komunikacji. To jednak byłoby zbyt proste. Mówię to, ponieważ to rozwiązanie zwyczajnie nie działa: istnieje parametr uruchomienia dotyczący wyboru interfejsów, ale komunikacja przebiega nieprawidłowo nawet wtedy. I problem nie znika do momentu zniszczenia interfejsu virbr0. Tak jest – zniszczenia. Nie można go po prostu przełączyć w tryb offline, bo od razu wstaje na nowo, zresztą to interfejs mostkowy i takie zachowanie jest poprawne. Konieczne jest usunięcie go, a to oczywiście ma swoje wady. Na przykład, gdy ktoś jednak zechce użyć wirtualizacji, to zostanie bez sieci. Zwracam tu uwagę na fakt, że serwerowe hypervizory działają nieco mniej przyjaźnie, niż taki VirtualBox, który odpala system w okienku. Tutaj bez sieci nie zrobimy nic. Odbudowanie tego interfejsu też jest nietrywialne. Póki co nikt tego nie potrzebuje, ale ponieważ powiedziałem to na głos, jeszcze dziś w nocy okaże się, że jest to niezbędna, kluczowa funkcjonalność.
Powstaje pytanie: jakim cudem to dotychczas działało? Przecież to gdy nie miało prawa działać. Co uległo zmianie? Nic. Sprzęt odpowiedzialny za routing się zmienił, i nic ponadto. Jakie to ma znaczenie? Może fakt, że interfejs fizyczny był offline przez godzinę sprawiło, że NetworkManager podniósł priorytet tego wirtualnego mostka? To w ogóle możliwe jest? Dokumentacja sugeruje, że priorytety interfejsów dotyczą zupełnie innych scenariuszy. A może dokumentacji po prostu (dalej) nie ma? Przecież nie dawniej, jak rok temu, gdy czytałem logi NM, natknąłem się na numer błędu tłumaczony na „jeszcze nieudokumentowane”. Dotyczył wszystkich zdarzeń płynących z karty sieciowej, a były to zdarzenia różne. I nie była to zasługa tego, że NetworkManager był „zbyt nowy”, bo pochodził z Fedory. Nie, nie. Poprzednia wersja w ogóle nie wypisywała nic na standardowe wyjście. Pamiętam jednak również, że w ogóle mnie to nie zdziwiło, pamiętam bowiem, że NM zrywał połączenia sieciowe przy wylogowaniu. Wynikało to z ubicia procesu nm‑applet i miało to miejsce w systemie Red Hat Enterprise Linux 5. Zawsze miałem podłe zdanie na temat NetworkManagera. Niby obecnie jest domyślną usługą w serwerach Red Hata i autentycznie odpowiada za cały ruch sieciowy, ale jak czasem czytam dzienniki zmian dla najnowszych wersji, dumnie ogłaszają one dodanie do NM jakiejś elementarnej funkcji, bez której sens całej usługi jest moim zdaniem poddawany ciężkiej próbie.

Dalej nie mam pojęcia, jakim cudem OpenMPI mógł się samoistnie popsuć, bo moim zdaniem to zwyczajnie niemożliwe, ale los zesłał mi inny podarunek, w postaci nowych komputerów do HPC, zaopatrzonych w karty graficzne AMD. Wiadomo powszechnie, że sprzętu od AMD nie wolno kupować, bo to samobójstwo i masochizm, a monopol Intel+NVidia nie powstał wskutek reptiliańskiego spisku, a dzięki rzeczywistej jakości. Próby instalacji sterownika AMD na Fedorze 21, mimo kilku (ale naprawdę niewielu) poradników, skończyły się niepowodzeniem. Sterownik po prostu nie chciał się zainstalować i kropka. Istnieją paczki RPM, nawet instalują się poprawnie, ale to nie ma znaczenia. Sterownik ewidentnie jest w systemie, ale nie chce się włączyć. „Zablacklistowanie” wszystkiego poza nim sprawia, że X11 po prostu wykłada się podczas uruchomienia. Ponownie zatem nawiedziła mnie myśl, żeby podbić system z wersji 21 do 22. Krótka wizyta na forum Fedory i zapoznanie się z morzem łez i potokiem narzekań na wyczyny AMD w kwestii sterownika sprawiły, że zrozumiałem, że na Fedorze 22 sprawa ma się jeszcze gorzej, niż na poprzedniej wersji. Nie był to jednak główny powód, dla którego nie przeprowadziłem tej aktualizacji. Było nim coś znacznie gorszego.
Wadliwe instalatory
Fedora 22 została wydana z krytycznym błędem w instalatorze Anaconda, który sprawia, że… nie uruchamia się konsola. Jakieś nieokreślone problemy z getty i systemd sprawiły, że na konsolę trzeba czekać kilkanaście minut, o ile w ogóle raczy się pojawić. To dość duży problem, bowiem moje instalacje dość mocno korzystają ze skryptów postinstalacyjnych, które uruchamiają się właśnie na tej konsoli, więc zdecydowanie jej potrzebuję, również po to, by mieć jakiegoś Linuksa możliwego do uruchomienia z PXE do celów diagnostycznych. Według mnie, taki błąd w ogóle powinien przekreślać całe wydanie i opóźnić je aż do momentu naprawy, ale zespół wydawniczy Fedory był innego zdania: ów błąd nie pojawił się na liście czynników blokujących wydanie i został naprawiony dopiero kilka tygodni po premierze Fedory 22. Co w dodatku nie miało większego znaczenia, ponieważ reguły wydawnicze (co jeszcze kilka lat temu nie było prawdą) zabraniają aktualizowania obrazów instalacyjnych. W ten sposób przez pół roku najnowsze wydanie Fedory było rozprowadzane z wadliwym instalatorem sieciowym. Nieźle. Swoją drogą, w czasach systemu „Red Hat Linux”, a ponieważ jestem mentalnym starcem to jakimś cudem to pamiętam, nie tylko wydawano poprawione obrazy instalacyjne, ale i publikowano erratę, w formie obrazów dyskietek. Uruchamiając instalator z odpowiednim parametrem, można było łatać Anacondę przed rozpoczęciem instalacji. W tej chwili jednak nie stosuje się prostych, skutecznych rozwiązań, a skomplikowane i wadliwe. Jak mawia mój szacowny znajomy:
Kiedyś było lepiej. Mimo, że było gorzej.
Jako, że Red Hat Enterprise nie wchodzi w grę, faktycznie musiałem zainteresować się CentOSem. Tutaj takie hece nie powinny mieć miejsca. Korzystając z okazji, jaką była migracja sprzętu, stworzyłem nowy serwer wdrażania, oparty właśnie na CentOSie, w założeniu instalujący właśnie CentOSy. Popełniłem jednak błąd, jakim było przekonanie przez ułamek sekundy, że wszystko będzie działać poprawnie. Los musiał się na mnie zemścić za tak zuchwałe myśli. Bowiem CentOS, podobnie jak wszystko inne, również nie działa. Pierwszy problem pojawił się bardzo szybko: pliki odpowiedzi instalatora wykładały się, ponieważ nie można było odnaleźć odpowiednich pakietów. Okazało się (co w sumie jest logiczne), że CentOS, jak i RHEL, składają się z wyraźnie mniejszej liczby pakietów, niż Fedora. Miałem nieszczęście nadziać się na kilkanaście z nich, w dodatku nie miałem tego jak ominąć, bo zwyczajnie były potrzebne. Tutaj z pomocą przyszło repozytorium EPEL, czyli coś na kształt dawnego „Fedora Extras”. Zawiera ono dużą część brakujących mi pakietów, kilku bardziej postrzelonych paczek musiałem się jednak pozbyć. Sterowniki graficzne można pobrać z repozytorium „elrepo” i to naprawdę wielka ulga, że ono istnieje. CentOS jest mniej „ruchomym celem”, niż Fedora, więc przygotowywanie takich paczek jest łatwiejsze, ale nie byłoby nic dziwnego w tym, gdyby nie było ich również dla CentOSa. Pogłoski wskazywały jednak, że zespół obliczeń rozproszonych używa tego systemu właśnie z własnościowymi sterownikami, więc byłem odrobinę spokojniejszy. Ale przecież coś musiało pójść nie tak.
RPM Fusion
Poza oprogramowaniem do HPC, potrzebny jest też soft do multimediów. A więc mplayer, vlc, mencoder, audacity-mp3 i inne takie. Nie są na Fedorze specjalnym problemem, bo przecież istnieje repozytorium RPMFusion. No to popatrzmy :
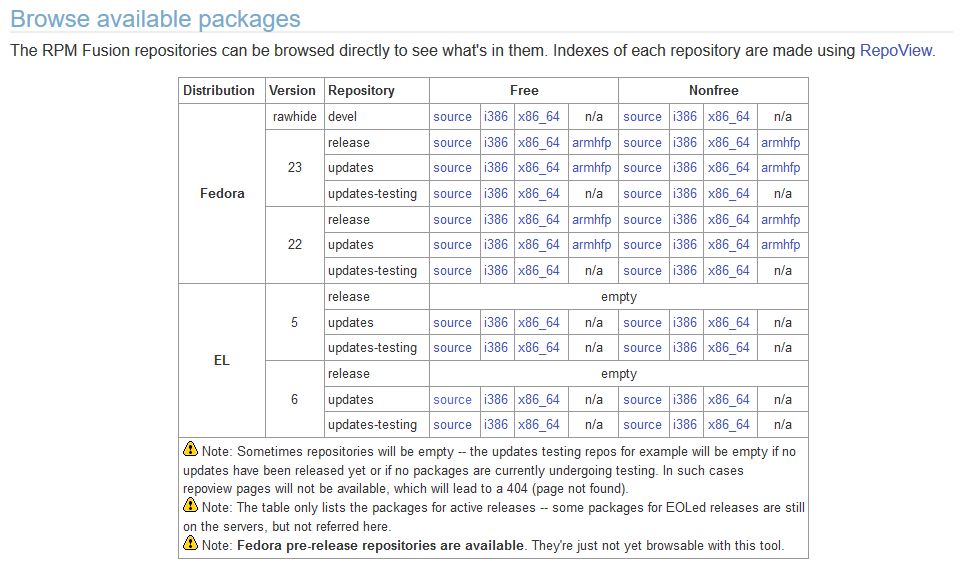
TAK! Właśnie tak – nie ma repozytorium RPM Fusion dla RHEL/CentOS w wersji 7 :D A więc zawsze coś musi być nie tak. Praktyka pokazuje jednak, że studenci informatyki tak panicznie boją się Linuksa, że uruchamiają VLC, Audacity i nawet nmap (a to już jest szaleństwo) pod Windowsem. Nie mówię tu tylko o tych przychodzących na zajęcia w dresie. Akceptowalnie dobrzy programiści-absolwenci, nieźle odnajdujący się na rynku pracy, coraz częściej nie mają elementarnej „informatycznej wiedzy powszechnej” i posadzenie ich przed Linuksem doprowadza do całkowitej bezradności. W każdym razie – RPMFusion nie ma, ale prawdopodobnie uda się ten problem odwlec w czasie. Był jednak nieprzyjemną niespodzianką. Kolejnym dowodem na to, że niezależnie od tego, jaki zestaw narzędzi się wybierze, zawsze coś będzie nie tak. I będzie tego wiadomo od razu – obowiązkowo trzeba się poparzyć. Potem intuicja podpowiada już, że „to wygląda zbyt pięknie i na pewno nie zadziała”, ale ani trochę nie jest to rozwiązanie: przecież tyle się słyszy o tym, że „nasze rozwiązanie naprawdę działa”.
Podsumowanie
Wiem, jak to brzmi – że winni są wszyscy wokół. Że brzmię jak typowy programista, który patrząc na czyjkolwiek cudzy kod mówi, że nikt poza nim nie potrafi programować, bo tego się przecież nie da czytać. Ale naprawdę faktem jest, że mimo ogromnego postępu, wszystko dalej działa na słowo honoru. Hyper-V też wywinęło niezłą akcję, przypominającą, że jest prawdziwym produktem Microsoftu. Pojawia się w tej historii, ponieważ serwer wdrażania, wraz z kilkunastoma innymi desktopowymi stacjami roboczymi, migruje (wreszcie) na serwer z porządną macierzą dyskową. Przyszło więc zwirtualizować tego CentOSa, umożliwić mu obsługę PXE i przydzielić kartę sieciową. Z wielu powodów, nie mogłem podpiąć karty sieciowej dla niego od razu. Wywołałoby to „pętelkę” w sieci i odłączyłoby od Internetu wszystkie laboratoria, bowiem ów serwer odpowiada także za routing. Dlatego należało najpierw ukraść kartę sieciową systemowi i oddać ją dla Hyper-V, a dopiero potem ją podpiąć do sieci, żeby faktycznie zachowywała się, jak karta należąca do innego komputera. Okazało się to niemożliwe. Kreator instalacji Hyper-V grzecznie i profesjonalnie pyta, którą kartę sieciową mu przydzielić, owszem. Ale na liście znajdują się tylko podłączone interfejsy! Musiałem więc najpierw podpiąć kartę, popsuć internet, przejąć ją dla Hyper-V, wyszarpać ją z systemu (bowiem Hyper-V i tak usiłował się z nim nią dzielić, przez co internet dalej nie działał), zrestartować routing, żeby internet wrócił i dopiero wtedy rozpocząć instalację wirtualnego systemu. Swoją drogą, może właśnie od tego przestał działać ten virbr0 w labie z OpenMPI…
To wszystko są problemy, które nie mają prawa mieć miejsca. Takie zachowanie jest całkowicie niedopuszczalne, niestety jednak występuje i nikomu nie da się tego wytłumaczyć. Nie wygłoszę powyższej tyrady swoim przełożonym, zresztą niewiele by z niej zrozumieli, a uproszczenie jej na tyle, żeby było to jasne dla osoby nietechnicznej sprowadza ją do postaci „powstały problemy techniczne”. Na co naturalną reakcją jest przecież „to proszę je rozwiązać”. A przecież użyłem jednak topowych rozwiązań. Nie ma lepszego Windowsa, niż Windows Server 2012 R2, podobnie jak nie ma lepszego Linuksa do firmowego wdrażania, niż Red Hat. Jeżeli ktoś myśli, że Ubuntu jest „łatwe” więc się tutaj sprawdzi, to polecam sprawdzić dokumentację, pełną magicznych zaklęć i ręcznych wycinanek w plikach konfiguracyjnych. A inne Linuksy to już w ogóle zabawki, tworzone przez 15 osób dla 40 użytkowników, zorientowane tylko na desktop i w dodatku nieradzące sobie z tym zadaniem szczególnie dobrze. Wiem, że tu przesadzam, ale porównawczo właśnie tak wygląda skala przepaści w materii rozwiązań firmowych.
Tak było od zawsze...
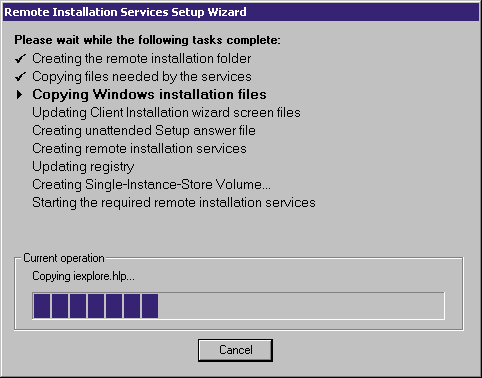
Nie chodzi mi tutaj o to, że „kiedyś działało”. Być może nabiera się takiego wrażenia, walcząc z problemami nieprzystającymi do roku 2015, ale cofając się w czasie można prędko zauważyć, że w przeszłości również nic nigdy nie działało. 10 lat temu PXE na płytach głównych stroiło straszne fochy, a „Remote Installation Services” dla Windows XP często wymagało logowania jako administrator na każdej zrobionej stacji, bo coś się nie doinstalowało, mimo, że sterowniki przeszły, a wszystkie programy były instalowane z paczek MSI. W dodatku system nie obsługiwał szeregu technologii, jak SATA, a przez długi czas nawet Bluetooth, USB 2.0 ani Wi‑Fi. 15 lat temu najpopularniejszym systemem był Windows 98 (i właśnie wyszedł jego młodszy brat z wodogłowiem, czyli Windows Me), system tak niestabilny i przestarzały, że trudno było zrozumieć, jakim cudem ludzie płacą za niego pieniądze. A nie mieli wyjścia głównie dlatego, że domowa wersja NT była spóźniona już jakieś trzy lata. 20 lat temu pracowaliśmy na ultratanich chińskich składakach z Optimusa, z deficytem RAMu (i kondensatorów na płycie) oraz systemem Windows 95, który nie obsługiwał AGP, ACPI, USB ani FAT32, a dodawanie łatek dostarczających obsługę tych elementarnych funkcji sprawiało, że system konał w konwulsjach, zmuszających do aktualizacji do wersji 98. Ćwierć wieku temu dzielnie używaliśmy 16‑bitowych graficznych nakładek bez paska zadań, pracujących na systemie, który nie widział więcej, niż 640 kilobajtów pamięci, używając do tego komputerów z 32‑bitowym procesorem i megabajtami RAMu. Oprogramowanie nigdy nie nadążało za sprzętem i zawsze było „beznadziejne”. Mam jednak wrażenie, że obecnie musimy rozwiązywać problemy, które już kiedyś rozwiązano (patrzę na ciebie, Windows 10. Nie chcę nawet myśleć, co się stanie, jak będę musiał cię wdrażać).
I wreszcie: proszę mnie tu źle nie zrozumieć :) Ja naprawdę lubię swoją pracę. Podoba mi się ten problem-solving, tak strasznie nudny i nieznany dla większości moich informatycznych znajomych, którzy zajęli się programowaniem. Po prostu czasem mi się wydaje, że byłbym w stanie zrobić więcej, gdyby oprogramowanie działało tak, jak piszą na pudełku. Ale historia uczy, że nigdy tak nie było i prawdopodobnie tak pozostanie już na zawsze :)

![Kompaktowy projektor ze wbudowanym Google TV. ViewSonic LX60HD [Recenzja]](https://v.wpimg.pl/Y2M0LmpwdlMsUjpeXwx7Rm8KbgQZVXUQOBJ2T19CYAU1A31bXwM8USUeOx0TEzccPVxjBB0QdlN6A3hVQEZvHyxUfVpdQ2pWeh11CRUUdAJ7Ai0OQEI7BS5TeEMaBz4QMA)
![Mroczna Rewolucja i Taktyczna Walka w Świecie Roguelite. Liberté [Recenzja]](https://v.wpimg.pl/OThlLnBuYDUJDjpdbQ5tIEpWbgcrV2N2HU52TG1AdmMQX31YbQEqNwBCOx4hESF6GABjBy8SYGddD34IcREpeV9ZdV9vQS02X0EuXnJFYjJdXC1XIRd8NlFUKUAyGyh2FQ)



![Ergonomiczna, bezprzewodowa klawiatura. Logitech Wave Keys [Recenzja]](https://v.wpimg.pl/M2EzLmpwYlMkGDpeXwxvRmdAbgQZVWEQMFh2T19CdAU9SX1bXwMoUS1UOx0TEyMcNRZjBB0QYgBwH3hbREF8H3JDLgldQy4CfVcuXRYSYAEmH3gORE8rAHYbf0MaByoQOA)
