

OpenEdge ABL/Progress 4GL
Cześć. Chciałbym dzisiaj przedstawić Wam OpenEdge Advanced Business Language (w skrócie OpenEdge ABL), czyli język programowania czwartej generacji. Został on stworzony przez amerykańską firmę Progress Software Corporation, a jego pierwsze wydanie wyszło już w 1984 roku. Początkowo język nazywał się PROGRESS, ale mówiono również Progress 4GL. Jest to bardzo słabo znany w Polsce język programowania, większość klientów to firmy amerykańskie, ale jest też pokaźna grupa firm europejskich. Z produktów i usług PSC korzystają również niektórzy giganci, tacy jak np. HP, T‑Mobile, Adobe, Toyota czy eBay. To tylko część z firm, które pozostawiły krótką historię ich problemu i w jaki sposób produkty i/lub usługi Progress Software Corporation pomogły im je rozwiązać. Więcej firm i ich historii znajdziecie pod linkiem https://www.progress.com/customers

Czym jest język czwartej generacji?
No właśnie, co to takiego język programowania czwartej generacji (w skrócie 4GL), czym się wyróżnia i jakie ma wady? Jak możemy przeczytać na polskiej wersji Wikipedii, 4GL to język, który pozwala za pomocą prostych i krótkich komend stworzyć program, który w językach niższej generacji wymagałby setek lub tysięcy razy większej liczby wierszy kodu źródłowego. Dodatkowym atutem 4GL jest możliwość wstawiania fragmentów kodu w językach 3GL. Wikipedia twierdzi również, że wyróżnikiem języka 4GL jest jego specjalizacja, czyli obszar w którym dany język będzie działał najlepiej, będzie najbardziej efektywnym narzędziem w danym obszarze zastosowania. I to w sumie tyle z polskiej części Wikipedii. Dużo więcej dowiemy się za to z angielskiej wersji, do której odsyłam wszystkich zainteresowanych ogólną definicją 4GL.
A jaki jest OpenEdge ABL?
Z Progressem (chociaż ta nazwa nie obowiązuje od 2006 roku) zacząłem przygodę, gdy podjąłem pracę w obecnej firmie i z racji, że na rynku ciężko znaleźć programistów tego języka, firmy same szkolą pracowników do jego obsługi. Po półtora roku pracy nadal wiem i umiem tylko małą część z całego zbioru jakim jest OpenEdge ABL, bo jest tego sporo. Własna relacyjna baza danych Progress, własne środowisko programistyczne i zbiór bibliotek oraz środowisko WebSpeed do tworzenia webserviców to tylko czubek góry lodowej. Nie jestem nawet w stanie opisać wszystkich możliwości tego języka, bo wiąże się z nim tak dużo usług i aplikacji, że aby poznać całość dogłębnie to trzeba byłoby udać się na kurs do samego PSC. Ale mogę za to opowiedzieć Wam to co wiem, a jeżeli temat Was zainteresuje, to przedstawię również przykładowe aplikacje napisane w Progressie. Coś co jest bardzo istotne, to fakt, że całe środowisko jest multiplatformowe, więc jakiekolwiek zmiany architektury sprzętowej lub systemowej nie mają żadnego wpływu na działanie aplikacji. Wszystko można przenieść na nowy system i będzie działało tak jak do tej pory!
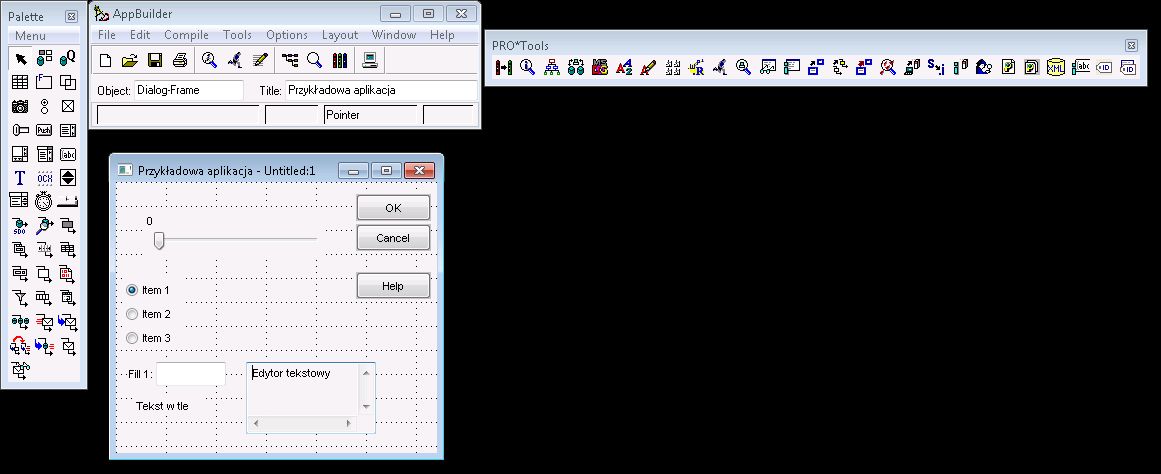
Sam język jest bardzo łatwy, w dodatku cały czas mamy dostęp do Helpa, który zawiera opis wszystkich poleceń razem z dokładnie opisanymi parametrami oraz podanymi przykładami użycia. Polecenia w większości są słownikowe, dzięki temu nawet jeżeli nie znamy jakiegoś, to i tak będziemy w stanie, w większości przypadków, domyślić się co dane polecenie robi. Trzeba również zaznaczyć, że zarówno język, jak i baza danych zorientowane są na transakcje, a co za tym idzie, wszystkie błędy jakie występują nie muszą być groźne w skutkach. Transakcje można zagnieżdżać w kodzie wielokrotnie, a to daje nam większą kontrolę nad aplikacją. Najprostsze aplikacje mogą być bez GUI, wtedy wykonują się w tle i widzimy tylko ich efekty, ale nie ma problemu ze stworzeniem aplikacji okienkowej. Możemy do tego celu sami napisać ręcznie kod odpowiedzialny za GUI lub skorzystać z narzędzi deweloperskich i układać elementy jak w edytorze WYSIWYG, nie ma z tym żadnego problemu. Jeszcze jedna, bardzo ważna, kwestia - wszystkie polecenia kończymy kropką, a nie średnikiem!
"Hello World", czyli podstawowe komendy
Do wyświetlenia zwykłego "Hello World" wystarczy nam dosłownie jedno polecenie. Tak, naprawdę. I tak, wiem, że w C wystarczy samo:

printf("Hello World");
i też wydrukuje się nam tekst na ekranie. Ale w Progressie nie potrzebujemy do tego żadnego maina, a dodatkowo wyświetlimy to w postaci okienka dialogu. Wystarczy jedno polecenie o treści:
MESSAGE "Hello World" VIEW-AS ALERT-BOX.
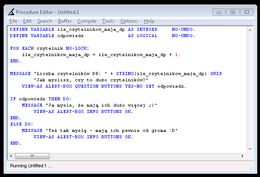
i to wszystko. Na poniższym zrzucie widzicie natomiast kod wygenerowany za pomocą dopełnienia. W edytorze wystarczy wpisać "m" i kliknąć spację, by pojawiło się całe polecenie, poza frazą "Hello World" oczywiście. Pozostaje nam dopisać to, co chcemy wyświetlić i polecenie gotowe. Teraz klikamy F2, czyli Run i naszym oczom ukazuje się Dialog-box widoczny na zrzucie. Dopełnień w Progressie jest naprawdę sporo i w większości składają się tylko z kilku literek - to naprawdę ułatwia i przyśpiesza pisanie kodu.
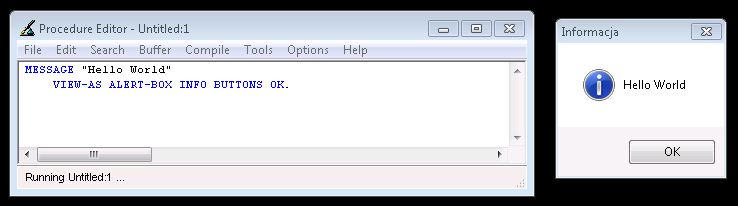
Widać również, jak logiczne są polecenia, każdy raczej domyśli się jaki będzie wynik polecenia MESSAGE, a "VIEW-AS" no to jak sama nazwa mówi - jak to ma być wyświetlone.
Ktoś może zapytać
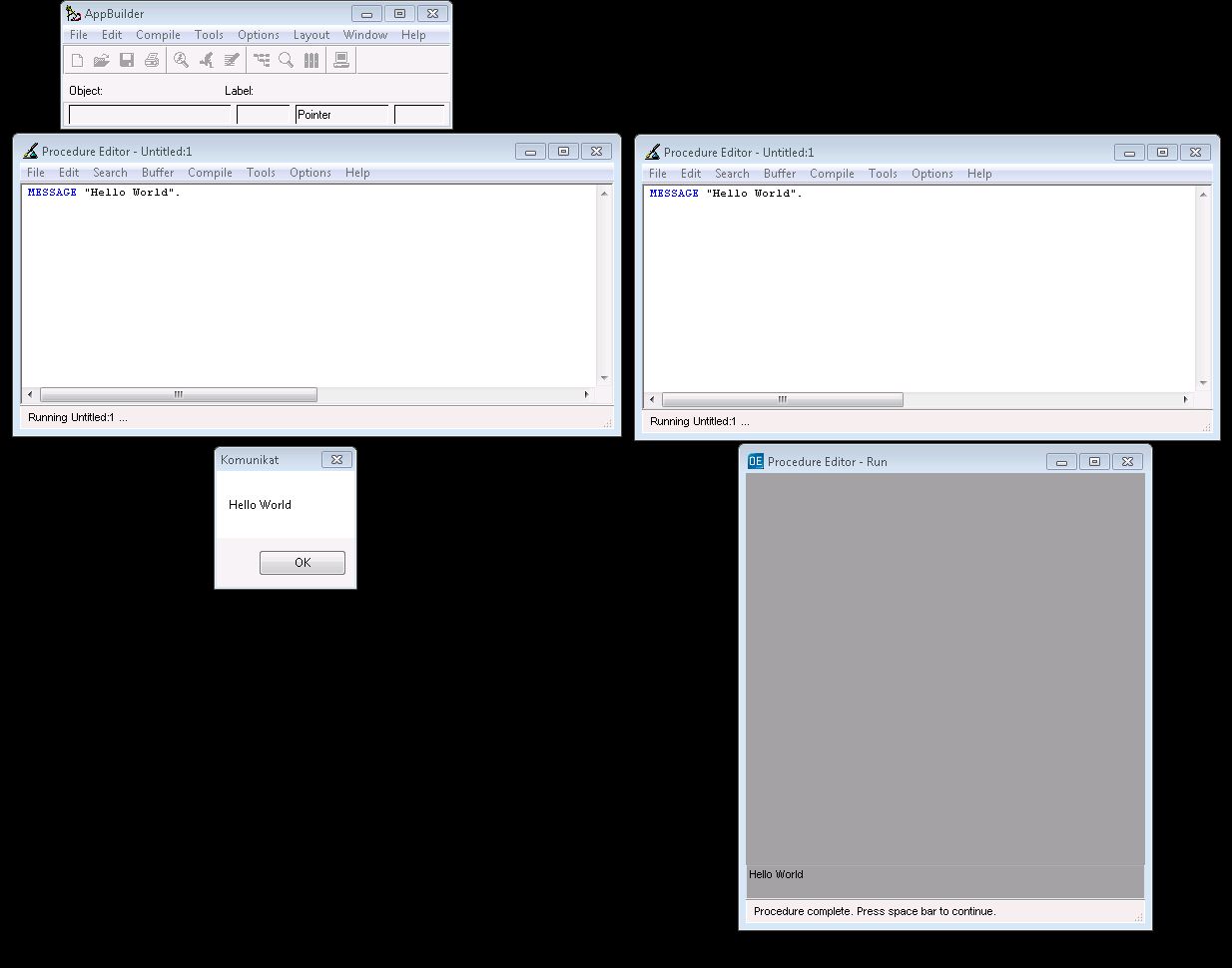
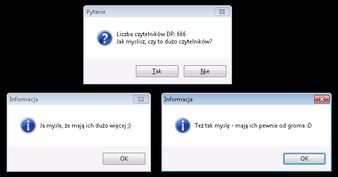
A co by się stało, gdybyśmy pominęli "VIEW-AS ALERT-BOX" z tej krótszej wersji polecenia?
To w sumie zależy z jakiego edytora korzystamy i jak są one ustawione. W jednym przypadku zadziałają domyślne wartości, w drugim otrzymamy wynik w czymś co możemy nazwać oknem rezultatów. Jak widać na poniższym obrazku, w pierwszym przypadku zadziałały wartości domyślne, czyli kompilator sam dopisał "VIEW-AS ALERT-BOX MESSAGE BUTTONS OK", bo taka jest domyślna wartość reszty parametrów.
W Progressie baza danych jest powiązana z samym kodem, nie ma osobnej warstwy dostępu do bazy danych, operuje się na niej tak jak na zmiennych w zwykłym języku. Tzn. nie zupełnie tak samo, ale miałem na myśli tutaj to, że nie musimy się do żadnej bazy podłączać, bo jesteśmy z nią od razu powiązani (za to odpowiada inna część środowiska). Jeżeli więc chcemy znaleźć jakiś jeden konkretny rekord w bazie danych to przykładowym poleceniem będzie:
FIND FIRST czytelnik WHERE czytelnik.imie = "Przemek" AND czytelnik.nick = "Kużdo" NO-LOCK NO-ERROR.
Jak widzimy, znów polecenie jest logiczne i z samych nazw można dojść do tego, co robi. W tym przypadku chcemy znaleźć pierwszy rekord o podanych danych. Do takiego wyszukiwania trzeba użyć parametru FIRST, dzięki któremu wyciągniemy tylko pierwszy pasujący rekord, jeżeli pominęlibyśmy ten parametr, to kompilator uzna, że wyszukiwanie ma być unikalne i podane dane muszą ograniczać dostępne rekordy do jednego unikalnego, w przeciwnym razie dostaniemy error o treści:
Więcej niż jeden rekord z czytelnik został odnaleziony w unikalnej instrukcji FIND.
A co jeżeli takich rekordów jest więcej, a my nie znamy np. unikalnego ID szukanej osoby? Istnieją dwa sposoby przeszukiwania wielu rekordów o takich samych warunkach i to tylko od nas zależy, którego sposobu użyjemy. Pierwszym sposobem będzie kontynuacja poprzedniego wyszukiwania za pomocą kolejnego polecenia różniącego się wyłącznie jednym parametrem - zamiast FIRST użyjemy NEXT - a całe polecenie wstawimy dodatkowo w pętlę REPEAT. Całość wygląda tak:
FIND FIRST czytelnik WHERE czytelnik.imie = "Przemek" AND czytelnik.nick = "Kużdo" NO-LOCK NO-ERROR. REPEAT: FIND NEXT czytelnik WHERE czytelnik.imie = "Przemek" AND czytelnik.nick = "Kużdo" NO-LOCK NO-ERROR. END.
Drugim sposobem jest użycie pętli FOR, która wg mnie jest o wiele lepszą opcją, ale nie zawsze nadaje się do użycia (ale o tym kiedy indziej). Kod dla pętli FOR wygląda następująco:
FOR EACH czytelnik WHERE czytelnik.imie = "Przemek" AND czytelnik.nick = "Kużdo" NO-LOCK: END.
Na pewno zgodzicie się ze mną, że jest to wygodniejszy sposób. Jest to też dużo bezpieczniejszy sposób, ponieważ w przypadku, gdy w bazie nie ma rekordów o podanych warunkach, wszystko co zostało zawarte w pętli FOR nie wykona się. W przypadku polecenia FIND jest z tym trochę inaczej i trzeba używać dodatkowych poleceń. W powyższych przykładach z FIND użyte zostały parametry NO‑ERROR, których zadaniem jest wyłączenie przerywania wykonywania programu w momencie napotkaniu błędu oraz blokowanie wyświetlania błędów użytkownikowi. Używa się tego, ponieważ w przypadku nie znalezienia żadnego zgodnego rekordu program zostanie w tym miejscu przerwany i wszystko co wykonało się do tej pory zostanie albo cofnięte zgodnie z transakcją, albo zostanie zapisane. Aby tego uniknąć stosujemy właśnie parametr NO‑ERROR.
Tylko jak rozpoznać, czy znaleziono jakiś rekord czy nie? Do tego służy polecenie AVAILABLE, które jako parametr przyjmuje nazwę rekordu jaki szukamy i w zależności od dostępności rekordu zwraca TRUE lub FALSE. Przykładowy kod wyszukujący pierwszego czytelnika spełniającego podane warunki i wyświetlający krótki komunikat z jego danymi wygląda następująco:
FIND FIRST czytelnik WHERE czytelnik.imie = "Przemek" AND czytelnik.nick = "Kużdo" NO-LOCK NO-ERROR. IF AVAILABLE czytelnik THEN MESSAGE czytelnik.imie SKIP czytelnik.nazwisko SKIP czytelnik.nick SKIP czytelnik.wiek VIEW-AS ALERT-BOX INFO BUTTONS OK.
Kolejnym parametrem, który został użyty zarówno w FIND jak i FOR jest NO‑LOCK. Jest to parametr określający dostęp do rekordu. W Progressie dostęp do danych jest bezpieczny i nie ma możliwości, by w tym samym momencie dwa programy edytowały ten sam rekord, co zapewnia nam spójność danych. Do wyboru są trzy wartości tego parametru: NO‑LOCK, SHARE-LOCK i EXCLUSIVE-LOCK. Zacznę jednak najpierw od czegoś innego. W popularnych bazach danych, w momencie gdy wyciągamy jakieś dane, są one przesyłane do klienta i nic więcej w bazie danych nie jest wykonywane. W Progressie wszystkie operacje na bazie danych oparte są o bufory. Bufor w popularnych bazach takich jak np. MySQL to nic innego jak pamięć cache, która przechowuje raz wyciągnięte dane dla ich szybszego odszukiwania. W Progresie bufor służy do przetrzymywania danych, na których obecnie operujemy, niezależnie od tego, czy chcemy je tylko odczytać bez ich modyfikacji czy modyfikować, czy tworzyć nowe rekordy. W momencie, gdy coś odczytujemy z bazy danych, zostaje to skopiowane do bufora o takiej samej nazwie, jak nazwa tabeli i z identyczną strukturą pól tabeli (chyba że zawęzimy wyszukiwanie do kilku pól). Gdy przechodzimy do następnego rekordu lub zwalniamy obecny rekord, sprawdzany jest bufor rekordu i jeżeli coś zostało zmienione, to jest to zapisywane do bazy danych (o ile mamy do niej dostęp), a bufor rekordu zostaje wyczyszczony i ewentualnie uzupełniony nowymi danymi. Gdy tworzymy nowy rekord to zostaje on utworzony najpierw w bazie danych, następnie jest uzupełniany domyślnymi wartościami pól, a dopiero później kopiowany jest do bufora rekordu, na którym dopiero pracujemy.
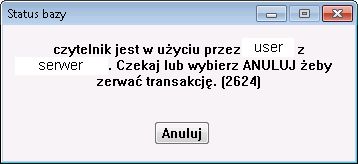
Wracając do tematu - parametr NO‑LOCK oznacza, że nie nakładamy żadnej blokady na rekord i nie mamy możliwości modyfikacji tego rekordu, dostępny jest tylko do odczytu. Pozwala to nam na dostęp do każdego rekordu jaki istnieje, niezależnie od tego, czy jest on modyfikowany przez kogoś innego czy ktoś inny założył na niego blokadę itp. My nie możemy go edytować, ale za to mamy nieograniczony dostęp w przeglądaniu. Kolejną wartością jest EXCLUSIVE-LOCK, które oznacza, że rezerwujemy rekord dla siebie i tylko my możemy go edytować, a reszta czeka w kolejce - tak, nie ma tutaj żadnego problemu w kolejkowaniu dostępu do rekordu. Powtarzając to co pisałem wyżej, polecenia z NO‑LOCK nadal mają dostęp do takiego rekordu i mogą go czytać nawet w momencie, gdy my go edytujemy. Jest to możliwe, dlatego że dane które modyfikujemy znajdują się buforze i dopiero na koniec są kopiowane do bazy, a dopóki to się nie stanie, to inne, równocześnie wykonywane polecenie pobiera dane do swojego buforu z bazy danych, czyli tę niezmodyfikowaną wersję.
Ostatnią możliwością jest SHARE-LOCK i jest to wartość domyślna, czyli gdy nie podamy żadnej z tych trzech wartości, to zostanie użyta właśnie ta. Jest to połączenie dwóch powyższych i działa w następujący sposób. W momencie, gdy pobieramy dane do odczytu, SHARE-LOCK traktowany jest jak NO‑LOCK, czyli każdy ma dostęp i każdy może zarezerwować sobie prawo do zapisu danych. W momencie, gdy zaczynamy modyfikować jakieś dane tego rekordu, to SHARE-LOCK jest podnoszony do EXCLUSIVE-LOCK i tylko my mamy dostęp do rekordu - o ile ktoś nas wcześniej nie uprzedził. Jeżeli ktoś nas jednak wyprzedził i edytuje już rekord, to dostajemy powiadomienie o tym, że rekord jest w użyciu i możemy zerwać swoją transakcję - dokładnie tak samo jak w przypadku kolejki opisanej przy EXCLUSIVE-LOCK. Ważna jest jeszcze jedna rzecz. W przypadku czytania rekordu, SHARE-LOCK jest traktowany jak NO‑LOCK, ale nie jest do niego zmniejszany. Skutek tego jest następujący - jeżeli ktoś zablokował rekord, nie ważne, czy poprzez EXCLUSIVE-LOCKa czy SHARE-LOCKa, my nie będziemy mogli go nawet odczytać. Dlaczego tak się dzieje? Ano dlatego, że w przypadku NO‑LOCK może dojść do sytuacji, w której odczytamy dane, które za sekundę będą już nieaktualne, bo ktoś je zmodyfikował. SHARE-LOCK blokuje wykonanie kodu dopóki ktoś nie zwolni rekordu i dzięki temu mamy pewność, że odczytujemy aktualne dane.
Typy, zmienne i tymczasowe tablice
Pokazałem Wam dzisiaj jak wyświetlać wiadomości na ekranie oraz jak wyszukiwać dane w bazie Progress. Jeżeli miałbym opisywać więcej poleceń, musiałbym poświęcić dwa razy więcej miejsca, dlatego na tę chwilę zatrzymamy się na tym, co już zostało napisane. Ostatnią rzeczą jaką chcę opisać (i obiecuję, że nie tak szeroko jak wcześniejsze akapity) to typy danych jakie występują w Progressie, jak tworzymy zmienne i jak wyglądają tablice tymczasowe.
Najczęściej używanymi typami danych są:
- CHARACTER - typ znakowy mieszczący 32Kb danych
- DATE - jak sama nazwa mówi, typ przechowujący datę
- DATETIME - typ z datą i czasem
- DECIMAL - typ liczbowy z częścią ułamkową, odpowiednik typów float i double
- HANDLE - wskaźnik do obiektu "Handle-Based", czyli wszelkiego rodzaju widgetów itp.
- INT64 - typ liczbowy 64-bitowy, odpowiednik uint/long
- INTEGER - typ liczbowy 32-bitowy, odpowiednik int/short/ushort/itp.
- LOGICAL - typ logiczny, odpowiednik typu boolean
- ROWID - unikalny wewnętrzny identyfikator rekordów w pojedynczej bazie danych, jeden ID = jeden rekord na całą bazę danych
Zmienne w Progressie tworzymy poleceniem:
DEFINE VARIABLE nazwa_zmiennej AS typ_zmiennej NO-UNDO.
W taki sposób tworzymy większość zmiennych. Parametr NO‑UNDO jest bardzo często wykorzystywany i jest powiązany z transakcjami. Gdy zmieniamy jakąś zmienną w transakcji i transakcja ta nie dojdzie do skutku, to wartość zmiennej jest przywracana do stanu sprzed zmiany, parametr NO‑UNDO blokuje to, dzięki czemu program oszczędza trochę czasu na przywracaniu danych. Zazwyczaj nie potrzebujemy przywracania poprzednich danych, bo większość zmiennych to zmienne przechowujące tymczasowe dane i nawet jeżeli transakcja nie dojdzie do skutku, to wartość tej zmiennej nie jest nam potrzebna. Polecenie DEFINE nie ogranicza się tylko do tworzenia zmiennych, za jego pomocą można też utworzyć inne obiekty np. obiekty interfejsu graficznego takie jak przyciski, obrazki, ramki, browsery, menu itp., bufory - co szczególnie przydaje się w przypadku pracy na kilku rekordach tej samej tabeli, zdarzenia takie jak kliknięcie LPM, 2x LPM, wpisanie czegoś z klawiatury itp., strumienie do plików i jeszcze kilka innych rzeczy, ale o tym (może) kiedy indziej.
Tablice tymczasowe w Progressie są bardzo często wykorzystywane, bo umożliwiają pracę na tymczasowych danych, które później bardzo łatwo przenieść do docelowej bazy. Można je tworzyć ręcznie, poprzez wypisanie wszystkich pól i indeksów oraz przez skopiowanie właściwości innej tabeli. Tworzymy je w taki sposób:
DEFINE TEMP-TABLE tt-czytelnik NO-UNDO FIELD id-czytelnika AS INTEGER FIELD imie AS CHARACTER FIELD nazwisko AS CHARACTER FIELD wiek AS INTEGER FIELD pesel AS INTEGER INDEX idx1 IS PRIMARY UNIQUE id-czytelnika INDEX idx2 nazwisko.
Ale możemy też napisać tak:
DEFINE TEMP-TABLE tt-czytelnik LIKE czytelnik.
I w ten sposób tworzymy tymczasową tabelę o strukturze identycznej jak tabela czytelnik.
To już jest koniec ...
... nie ma już nic. Jesteście wolni, możecie iść ;) A tak na serio, to planowałem zrobić z tego wpisu taki mały wstęp do Progressa, żeby zainteresować nim czytelników. Wpis się rozciągnął i szczerze powiedziawszy ciężko jest mi ocenić czy mógłbym coś stąd wyrzucić do osobnego wpisu tak, żeby ten wpis nadal pozostał "pełny" i zainteresował może kilka osób. Do opisania jest dużo, dużo, dużo więcej rzeczy i chętnie to zrobię, jeżeli kogoś zainteresuje ten temat. Jak może ktoś zauważył, nie ma opisanych wad języka 4GL, a takie pytanie zadałem w którymś z pierwszych akapitów. Ten temat też jest dosyć obszerny i wolałbym go jednak zostawić na osobny wpis. Podzielę się teraz z Wami tylko jedną wadą i to dotyczącą Progressa, a nie samego 4GL. Całe środowisko OpenEdge ABL jest niestety płatne, więc nie będziecie w stanie za darmo stworzyć aplikacji, którą będziecie mogli używać. Można pobrać wersję trial na 60 dni (przy czym trzeba być firmą lub wpisać fikcyjne dane :)) i można jej używać tylko w celach niekomercyjnych.
Wszystkim, którzy dotrwali do końca tego wpisu serdecznie dziękuję za poświęcenie mu (i mi również) swojego cennego czasu i jednocześnie przepraszam, bo jestem świadom tego, że wpis nie jest napisany idealnie. Może on zmęczyć kogoś, może być napisany złym językiem, dlatego z góry dziękuję za wszelkie komentarze (te negatywne i pozytywne) oraz spróbuję pisać kolejne wpisy z uwzględnieniem uwag, które do mnie dotrą.
W najbliższych dniach planuję również napisać kilka innych wpisów, m.in. o narzędziu flexget, którego - jak sprawdzałem - jeszcze nikt tutaj nie opisał. Czekam również na komentarze, czy podobał się Wam ten wpis, czy zainteresował Was on i czy jest coś o czym szczególnie chcielibyście poczytać. A może macie pomysł na przykładową aplikację w Progressie?
PS. Jak już pewnie dało się zauważyć na podstawie wpisu, mam na imię Przemek, mówią mi Kużdo i jestem programistą ;) Cześć!
